Paper Read 12 - Imitation Learning
Imitation Learning: An Introduction
在传统的强化学习任务中,通常通过计算累积奖赏来学习最优策略(policy),这种方式简单直接,而且在可以获得较多训练数据的情况下有较好的表现。然而在多步决策 (sequential decision) 中,学习器不能频繁地得到奖励,且这种基于累积奖赏及学习方式存在非常巨大的搜索空间。而模仿学习 (Imitation Learning) 的方法经过多年的发展,已经能够很好地解决多步决策问题,在机器人、NLP 等领域也有很多的应用。
模仿学习是指从示教者提供的范例中学习,一般提供人类专家的决策数据 \(\left\{\tau_1, \tau_2, \ldots, \tau_m\right\}\) ,每个决策包含状态和动作序列 \(\tau_i=<s_1^i, a_1^i, s_2^i, a_2^i, \ldots, s_{n_n i+1}^i>\) ,将所有「状态-动作对」抽取出来构造新的集合 \(\mathcal{D}=\left\{\left(s_1, a_1\right),\left(s_2, a_2\right),\left(s_3, a_3\right), \ldots\right\}\) 。
之后就可以把状态作为特征 (feature),动作作为标记 (label) 进行分类 (对于离散动作) 或回归 (对于连续动作) 的学习从而得到最优策略模型。模型的训练目标是使模型生成的状态-动作轨迹分布和输入的轨迹分布相匹配。从某种角度说,有点像自动编码器 (Autoencoder) 也与目前大火的 GANs 很类似。
在简单自动驾驶任务中 (如下图),状态就是指汽车摄像头所观测到的画面 \(o_t\) (很多强化学习任务中 \(o_t\) 和 \(s_t\) 是可以互换的),动作即转向角度。根据人类提供的状态动作对来习得驾驶策略。这个任务也叫做行为克隆 (Behavior Cloning),即作为监督学习的模仿学习。
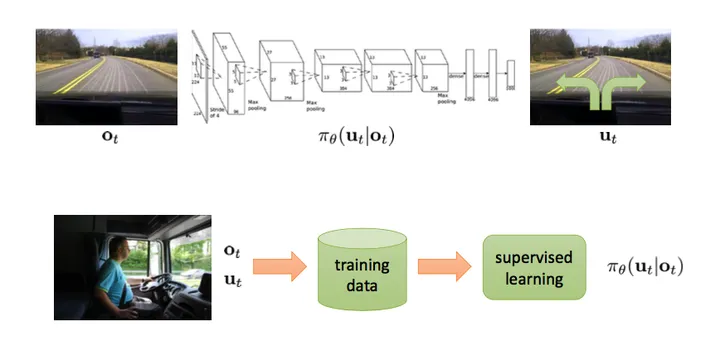
但是不是我们完成训练后模型就能够有比较好的效果?
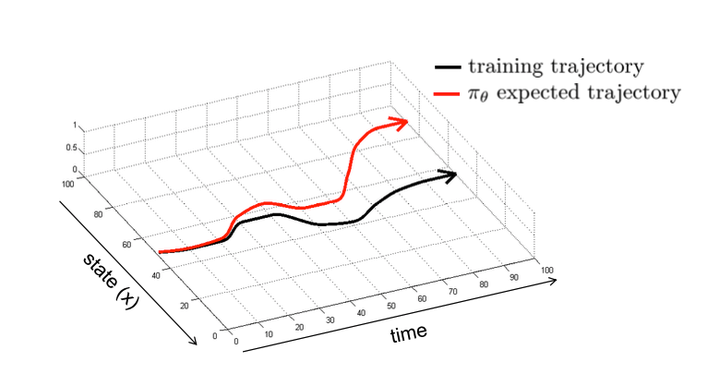
答案是否定的,这里存在复合误差 (compounding errors),训练好的策略模型 \(\pi_\theta\) 执行的轨迹和训练轨迹的误差会随时间的增加而越变越大,用公式表示即\(E[\)errors\(] \leq \varepsilon(T+(T-1)+(T-2)+\ldots+1) \propto \varepsilon T^2 \quad(\varepsilon\)代表在 \(\mathrm{t}\) 时刻 \(\mathrm{c}\) 误差的概率,在每个时刻 \(\mathrm{T} , E[\) errors \(] \leq \varepsilon T)\) ,具体效果见下图:
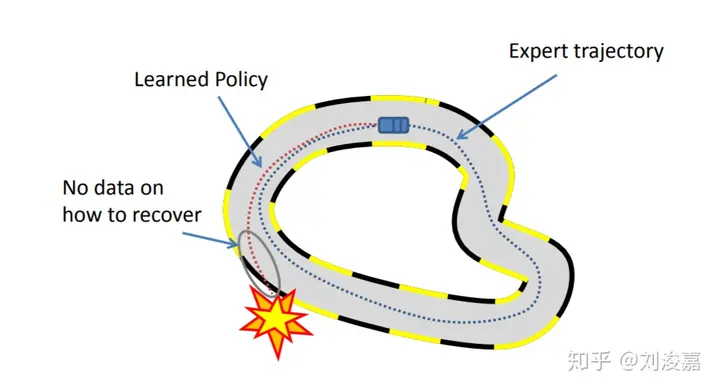
For a human, we take corrective actions when we drift off-course. Let’s suppose we want to drive straight in an intersection. Let’s say we are slightly off-course to the left. As a human, we take corrective action to steer back to the right.

collection expect demonstrations:费时费力,还需要大量数据样本进行监督学习训练。此外,只能收集到好的示范,会导致事故的示范很难收集。
数据增广(Data Augmentation)
| 2016 | Paper | Nvidia | End to End Learning for Self-Driving Cars |
为了解决误差随时间越来越大的问题,可以采用数据增广(Data Augmentation)方法,如下图,这是一个端对端的自动驾驶解决方案(NVIDIA 2016),汽车装配了左右两侧的摄像头与中央摄像头来获取当前观测的环境,并且能够通过 Back propagation 使其从错误状态中恢复。它在训练模型前人为地调整了环境不好时汽车的运动动作,另外,摄像头图像的识别采用的是卷积神经网络。
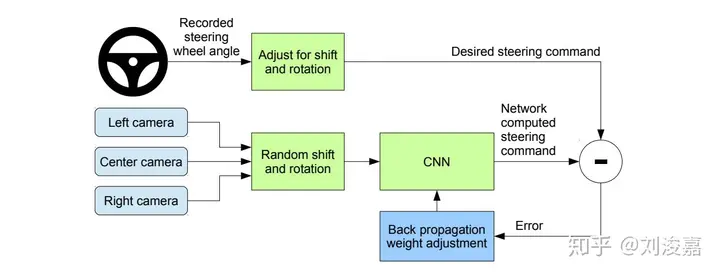
如果我们能够获取大量的训练数据形成一个合适的状态概率分布或者说样本空间,从而得到一个很好的策略模型同样能直接地解决这个问题。但这往往不太现实,因为需要耗费的成本太大。起初大部分研究者也几乎全在研究如何优化策略减少误差,并提出了很多方法,但都不是十分有效。
DAgger (Dataset Aggregation)
| 2010 | Paper | A Reduction of Imitation Learning and Structured Prediction to No-Regret Online Learning |
该方法则将研究目的从优化策略 \(\pi_\theta\left(u_t \mid o_t\right)\) ,即令 \(p_{\pi_\theta}\left(o_t\right)\) 趋近 \(p_{d a t a}\left(o_t\right)\) ,转移到增加训练数据上,即令样本空间更加接近真实样本空间。具体算法如下:
- 通过数据集 \(\mathcal{D}=\left\{\left(o_1, a_1\right),\left(o_2, a_2\right),\left(o_3, a_3\right), \ldots\right\}\) 训练出策略 \(\pi_\theta\left(u_t \mid o_t\right)\)
- 执行 \(\pi_\theta\left(u_t \mid o_t\right)\) 得到一个新的数据集 \(\mathcal{D}_\pi=\left\{o_1, o_2, o_3, \ldots\right\}\)
- 人工给 \(\mathcal{D}_\pi\) 中的状态标上动作 (action) \(u_t\)
- 聚合 (Aggregate) \(: \mathcal{D} \leftarrow \mathcal{D} \cup \mathcal{D}_\pi\)
- 跳到步骤 1

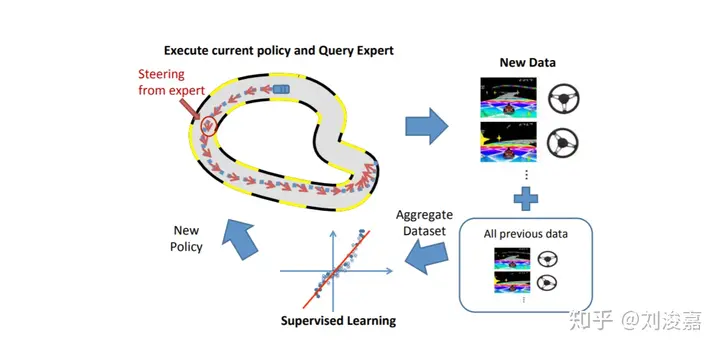
对模仿学习的应用场景而言,在仅仅使用模仿学习算法本身时,没有具体的理论去说明模仿学习什么时候表现好,什么时候表现不好,但很多时候都得不到很好的效果。它通常在下面几种情况里表现很好:
- 有很好的观测器,比如前文提到的左右摄像头引入了更强更丰富的状态信息
- 数据取样自一个很健壮的路径规划分布
- 增加更多在线策略生成的数据,比如使用 DAgger
下面是 CS294-112 中提到的模仿学习的两个具体应用:
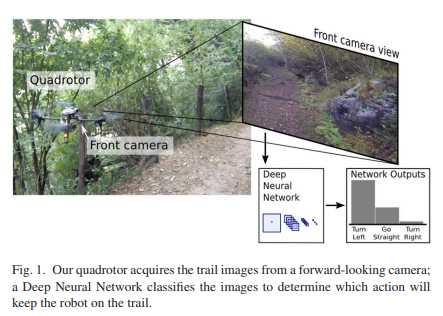
案例一 (下图) 是通过三个摄像头采集的图像描述 \(s_t\) ,人类行走的方向作为 \(u_t , u_t\) 拥有离散的三个量,直走 (straight) 、右转 (right) 和左转 (left)。获得数据后直接作为分类问题 (classification) 进行训练,取得了比较好的效果。
A Machine Learning Approach to Visual Perception of Forest Trails for Mobile Robots
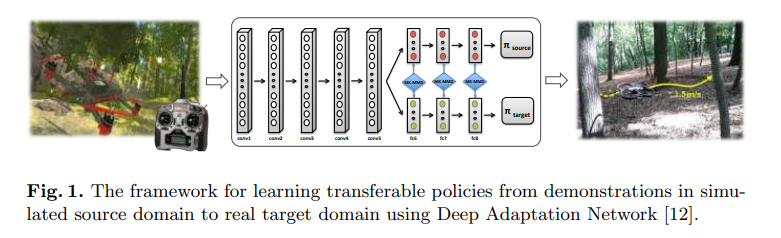
案例二使用了前面提到的 DAgger 方法,图中红线的位置是每个状态的标记,第三步即人工拖拽红线到合适的位置。
Learning Transferable Policies for Monocular Reactive MAV Control
从上述步骤中,我们可以看到 DAgger 最大的问题是第三步,第三步需要人为地去打标记,这是没有人愿意干的工作。那「自动」地办法代替人完成这个工作呢?答案是肯定的。

In fact, during training, we can deploy expensive sensors to measures the states of the environment. With fancy optimization methods, this may plan actions as good as a human and provides expert trajectories for us to imitate. But for the solution to be financially viable, we need to train the second policy without those expensive sensors.
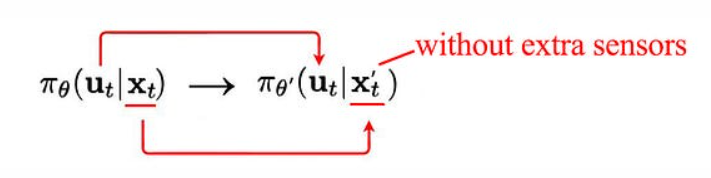
For example, our self-driving cars may have LIDAR, RADAR and video cameras during training to observe the environments. But for mass production, we may drop the LIDAR because of the cost. Here, we force the supervised training for a second policy to imitate the first policy but without the expensive sensors. Those state information needs to be extracted from the video camera directly. This is like a divide-and-conquer concept. The first policy focuses on the complex trajectory optimization using those extra states and the second one focus on the feature extraction.
Partially Observable Markov decision process

In one of the previous example, the challenge is not necessary on the missing training data. From the image above, are we trying to go left or go right? In some cases, objects may be obstructed in the current frame. Therefore, we cannot determine our action from a single frame only. We need history information. There are two possibilities to address this. In the first approach, we concatenate the last few image frames and pass it to a CNN to extract features. Alternatively, we use an RNN to record the history information as below:
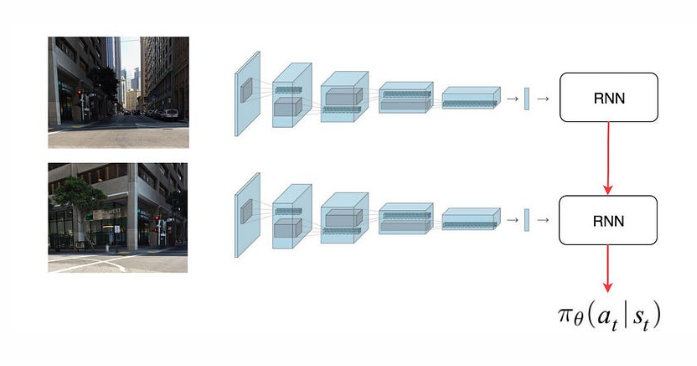
Imitation Learning v.s. Reinforcement Learning
Imitation Learning requires expert demonstrations which are often supplied from human experts. But in Guided Policy Search or PLATO, it is provided by a trajectory optimization method or a system that has better access to the states. In imitation learning, we deal with drifting where no expert demonstration is available. RL is often not very stable and not easy to converge. Imitation Learning uses supervised learning which is heavily studied with more stable behavior. But the trained policy is only as good as the demonstrations.
In reinforcement learning, we need to know the rewards function directly or through observations. Its success depends heavily on how well we explore the solution space. But it has no limit on how good the policy can be.
So can we combine both together? The expert can tell us where to explore which save the RL a lot of effort? And we can apply RL to refine a policy better than a human and able to handle the off-course situations better.
Pretrain & finetune
The first approach uses the expert demonstration to initialize a policy. This jumps start the search. Then we apply RL to improve the policy and to learn how to deal with those off-course scenarios.

While RL can improve the policy, it can still produce bad decisions that make the policy worse. As more bad decisions are made, we forget what we learn from the expert demonstration.

结构化预测 (Structured prediction)
结构化预测问题由输入空间 \(\mathcal{X}\) ,输出空间 \(\mathcal{Y} , \mathcal{X} \times \mathcal{Y}\) 服从的一个固定但未知的分布 \(\mathcal{D}\) 和一个非负的损失函数 \(l\left(y^*, \hat{y}\right) \rightarrow \mathbb{R} \geq 0\) 组成。其目的是用样本中的数据习得能最小化损失的映射 \(f: \mathcal{X} \rightarrow \mathcal{Y}\) 。下面是使用结构化预测在 Sequence labelling 中的几个样例:
- Part of speech tagging(语言词性标记)
x = the monster ate the sandwich
y = Dt Nn Vb Dt Nn
- Name Entity Recognition(名字检测)
x = yesterday I traveled to Lille
y = - PER - - LOC
下面是结构化预测在强化学习中的定义:
Sequence labelling x = the monster ate the sandwich y = Dt Nn Vb Dt Nn
- State: 输入序列 x 和已经生成的标签
- Actions: 下一个输出的标签
- Reward: 当预测值和真实值符合时,reward > 0
强化学习中的模仿学习
RL 的 reward func designing 一直备受诟病,而模仿学习似乎提供了解决方案。通过expert data构造这个reward func就是IL+RL的思路。
Model-Free Imitation Learning with Policy Optimization
| 2016 | Paper | OpenAI |
这篇文章是在吴恩达提出的学徒学习Apprenticeship Learning的基础上进行神经网络化,从而使用Policy Gradient方法来更新网络,基本思想是利用当前策略的样本和专家样本估计出一个Reward函数,然后利用这个Reward进行DRL。然而很多实际场景中的动作好坏与否即使人也很难界定,所以这个方法在复杂场景难以work。
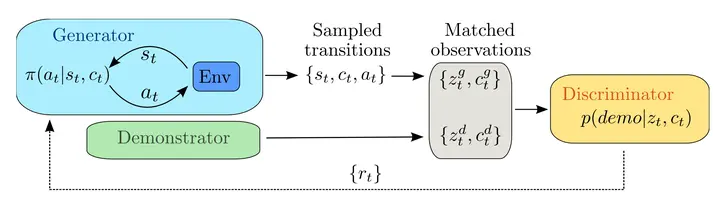
Generative Adversarial Imitation Learning (GAIL)
| 2016 | Paper | OpenAI |
将GAN引入到Imitation Learning:
- Generator用于生成动作序列,可以使用一些model-free方法;
- Discriminator则用于区分这个动作序列是否属于expert动作,其输出就可以作为reward使用。
GAIL的目标是使生成的动作和专家动作越来越接近。基于GAN的Imitation Learning这个做法非常的novel,换了一种方式来获取Reward(也可以说绕开了人为设定Reward的方式),可能最大的问题就是训练的效果可以达到怎样的程度。
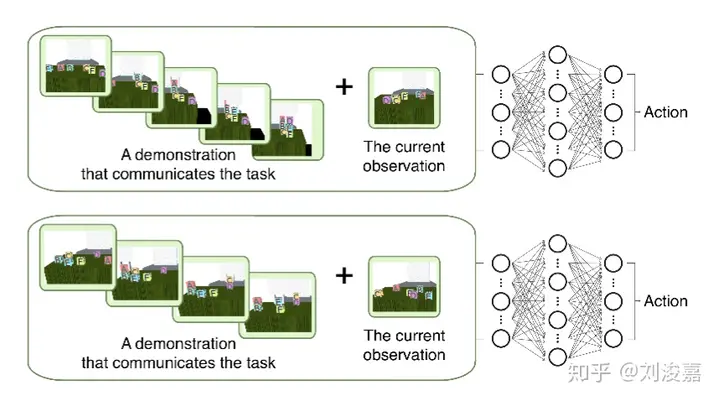
One-Shot Imitation Learning
| 2017 | Paper | OpenAI | Blog |
Yan Duan, Marcin Andrychowicz, Bradly C. Stadie, Jonathan Ho, Jonas Schneider, Ilya Sutskever, Pieter Abbeel, Wojciech Zaremba
One-Shot这个词不出所料地出自Abbeel组,之前的Meta-Learning:An Introduction系列涉及了一些。
依旧是meta的思想,训练集是demonstration数据+当前state,输出是action。
Third-Person Imitation Learning,
| 2017 | Paper | OpenAI |
这个工作的重点在于使agent可以通过第三视角学习demonstration,这就可以让它看视频学习了。
思路也很简单,在之前GAIL的基础上又加入了一个GAN,用于判断视角并使其能够在不同视角下提取出相同的feature。
Learning human behaviors from motion capture by adversarial imitation
| 2017 | Paper | Deepmind | Blog |
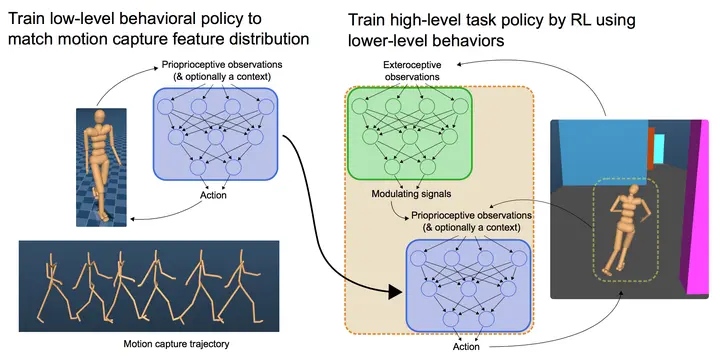
通过motion capture(动作捕捉)获取expert数据,依然是GAIL的结构,只是Discriminator不需要输入action,只需要state即可