Paper Read 9 - slides: Controlling Robots via Large Language Models
A short post, as I have only started learning llm + robotics in the last few days, I am not familiar with the feasibility, difficulties and pain points of this field. I read a blog with a comparative explanation and took notes.
Problem
Firstly it was mentioned that controlling robots these days is very rigid, that is to say not flexible enough. Debugging and programming for single or specific task engineers, there is not a flexible re-programmable way to adapt to various tasks.

So how do you free up engineers to achieve the task of programming robots to achieve tasks using only instructions in natural language? This is where LLM plays a key role.

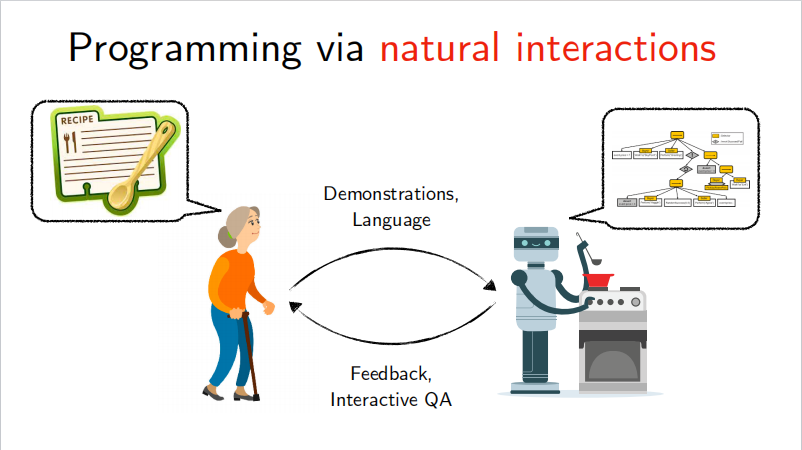
How things worked pre-LLM
It then talks about the two key challenges of pre-LLM:

- Grounding: Mapping language to robot’s internal state
- Planning
Grounding
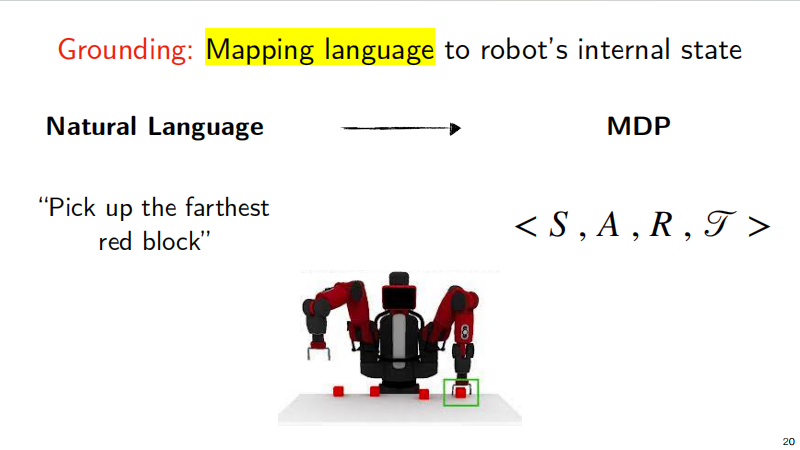
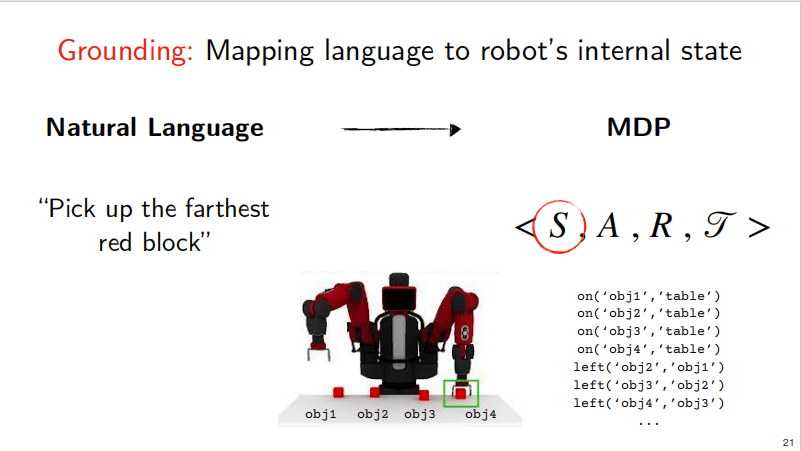
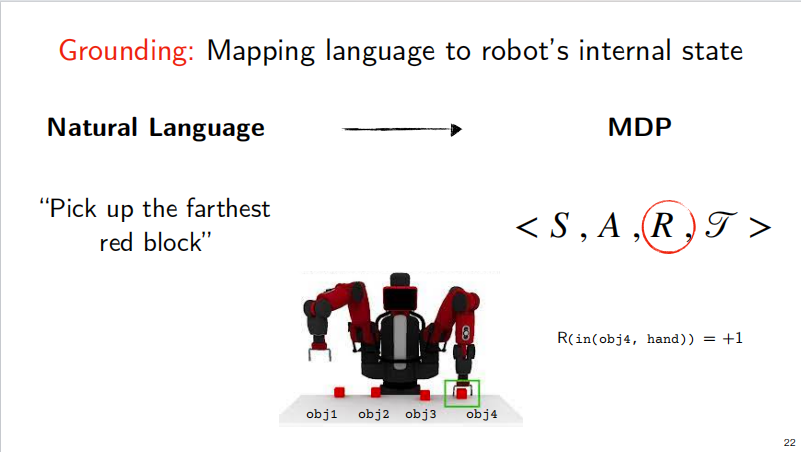
For example, if I want the robot to grab the leftmost red square located on a table, here I have to solve the problem of locating the table, the object on the table, the red square, and the relative positional relationship. If expressed in a logical language, it should be as follows:
Planning
Task planning is very important for robot operation, and is designed to how tasks can be rationally disassembled and executed. For example, the following example puts apples from the shelf on the table:
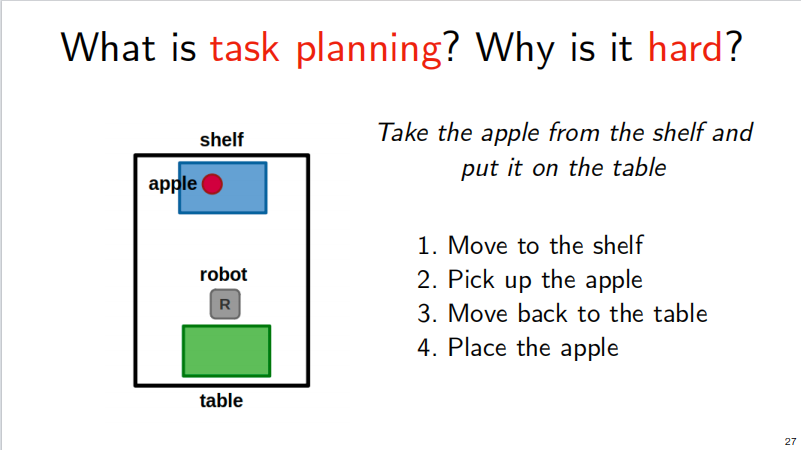
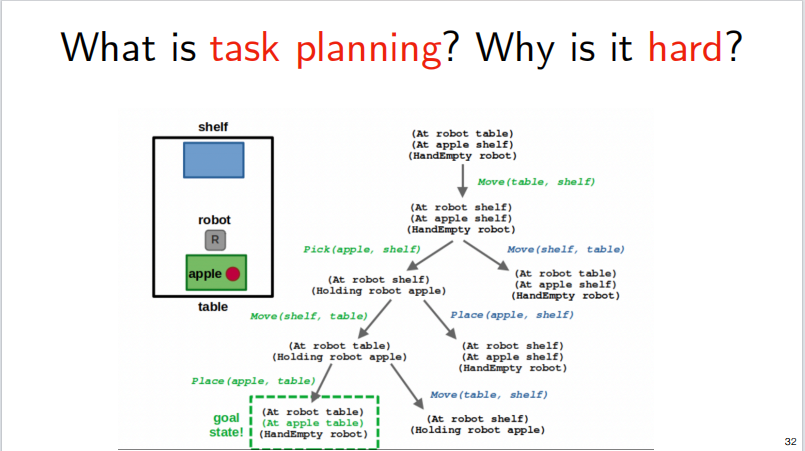
The flow chart for the completion of this task is shown below, and you can see that this execution process increases with the complexity of the task:
LLM Robotics
SayCan
SayCan dialogues through LLM and then provides a set of optional action lists to select the most appropriate action at the moment by employing value funcions trained by reinforcement learning.
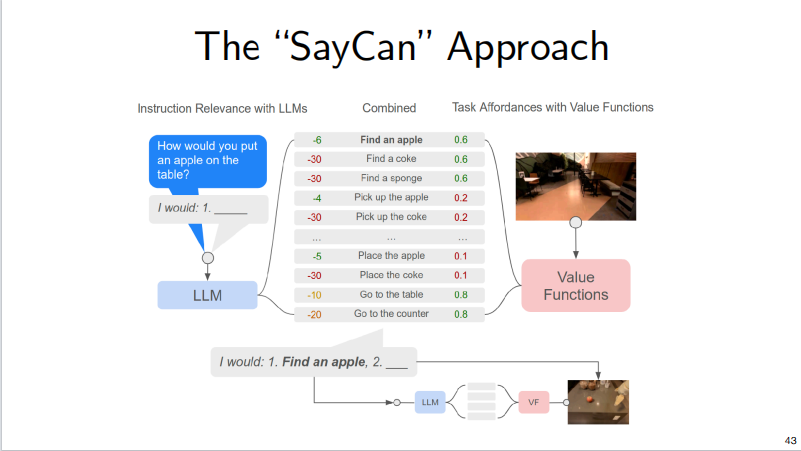
How does SayCan solve with grounding and planning?

Essentially dealing with grouding through LLM’s internal state and task planning through chain of thought. But there are still problems:

Problem1: **What if actions **fail?
Paper: Inner Monologue: Embodied Reasoning through Planning with Language Models

Inner Monologue deals with failures by having the LLM build a closed loop feedback system that constantly gets different forms of feedback (scenario description, success or failure):

Inner Monologue enables grounded closed-loop feedback for robot planning with large language models by leveraging a collection of perception models (e.g., scene descriptors and success detectors) in tandem with pretrained language-conditioned robot skills. Experiments show our system can reason and replan to accomplish complex long-horizon tasks for (a) mobile manipulation and (b,c) tabletop manipulation in both simulated and real settings.
Problem2: **How do we **verify correctness?
Paper:Code as Policies: Language Model Programs for Embodied Control

Given examples (via few-shot prompting), robots can use code-writing large language models (LLMs) to translate natural language commands into robot policy code which process perception outputs, parameterize control primitives, recursively generate code for undefined functions, and generalize to new tasks.

Conclusion
This slideshow focuses on two of the difficulties of doing robot control in pre-LLM (grounding, planning), then introduces SayCan’s ability to grounding and Chain of Thoughts planning with the help of LLM’s internal knowledge, and also introduces two problems of LLM Robotics, how to deal with failure and verify correctness. Inner Monologue deals with failure by building a closed-loop system that gets different forms of feedback; Code as Policies generates code by iterating code that modifies and complements the previous code to generate more complex and reliable code.