Paper Read 8 - PaLM-E: An Embodied Multimodal Language Model
Recently, when I saw the unmanned system of Westlake University’s explanation of Embodied Intelligence: Large Language Models Enabling Manipulators Planning and Control, it was mentioned that the intelligent capability brought by LLM makes robots smarter, more flexible, and capable of adapting to complex operation scenarios. So I read the paper of Google’s PaLM-E mentioned in the article, and the record is as follows.
Since I only know about the robotics field before, and the main body of the paper is in the NLP field, I decided to record the reading process in Chinese to facilitate my understanding.
前言
这篇论文的名字是 “具身多模态语言模型”(Embodied Multimodal Language Model),先来分析一下这个名字:
具身(Embodied):表示该模型接入了机器人,具有了身体。
多模态(Multimodal):表示该模型的输入是多模态的,包括文本(textual input encodings)、视觉(visual)、连续状态估计(continuous state estimation)。
语言(Language):表示该模型的输出只有文本。虽然说输出只能是文本,但是这个输出不再限制于自然语言。因为代码本身也是文本,所以模型的输出可以是一段代码,代码执行完之后可以是一段机器人可识别的指令;也可以模型直接输出机器人可识别的指令;这样模型的输出结果就可以操作机器人。
摘要
论文提出了具体化的语言模型,以将真实世界的连续传感器模态直接结合到语言模型中,从而建立单词和感知之间的联系。具体语言模型的输入是多模态语句,它们交织了视觉、连续状态估计和文本输入编码。
结合预训练的大型语言模型,对这些编码进行端到端训练,用于多个具体任务,包括顺序机器人操作规划、视觉问题解答和图像视频字幕描述。
论文的评估表明,PaLM-E可以在多个实施例上处理来自各种观察模式的各种体现推理任务,并且进一步表现出积极的迁移:该模型受益于跨互联网规模的语言、视觉和视觉语言领域的各种联合训练。
本文贡献
- 提出并验证了可以通过将具身数据混合到多模态大语言模型的输入中来训练出一个通用的、可迁移的、多决策的 agent。
- 证实了虽然现有的 zero-shot 图像语言模型不能很好的解决具身推理问题,但是训练一个具有通用能力的、能够解决具身推理问题的图像语言模型是可行的。
- 关于如何训练上述具身多模态语言模型,本文提出了新颖的模型架构和训练策略。
- 本文提出的 PaML-E 除了能解决具身推理问题外,在常规的图像和文本任务领域效果也很好。
- 最后,本文证明了随着模型规模的增大,可以有效缓解模型在多模态微调时的灾难性遗忘问题。
模型结构
该模型的基座是之前 google 发布的预训练模型 PaLM,然后接上机器人,也就是具身,所以该模型的名字为 PaLM-E(PaLM + Embodied)。既然基座是 PaLM 模型,那么该模型就是 Decoder 模型。
模型 PaLM-E 的输入有三种类型:文本、图像、连续状态(来自于机器人的各种传感器的观测结果)。输入中的连续状态和输入中的文本一样,映射到相同维度的向量空间中之后输入到模型中。在输入模型时文本、图像、连续状态这三部分的顺序是不固定的,有可能交替出现,比如以如下这种方式:
Q: What happened between <img 1> and <img 2>?
其中<img i>表示图像的嵌入。
该模型的输出是仅有文本输出,这些文本输出可以是问题的答案,还可以是PaLM-E以文本形式生成的决策/计划,用于控制机器人的底层行为,论文假设存在一个低级策略或计划器,可以将这些决策转化为低级行动。在本文中重点研究的就是用模型的输出控制机器人的决策。
模型结构公式
Decoder语言模型:
最经典的GPT结构,给定前面序列的token,预测联合概率最大的下一个token。公式如下:
\[p\left(w_{1: L}\right)=\prod_{l=1}^L p_{L M}\left(w_l \mid w_{1: l-1}\right)\]该公式中 \(p\left(w_{1: L}\right)\) 是总共 \(L\) 个token的联合概率, \(p_{L M}\) 是语言模型。
带有Prefix的Decoder语言模型:
在经典的GPT模型的基础上,在每条文本数据前面添加上一段prefix prompt。这个prefix prompt 可以是离散的,也可以是连续的。公式如下:
\[p\left(w_{n+1: L} \mid w_{1: n}\right)=\prod_{l=n+1}^L p_{L M}\left(w_l \mid w_{1: l-1}\right)\]在上述公式中,位置 1 到位置 n 是prefix prompt,从位置 n+1 往后是输入的文本数据。在训练时,prefix prompt部分不参与计算loss。
文本 Token 的嵌入空间:
定义一下符号,因为下一部分会需要将从传感器获取到的连续状态也映射到这个同维度的向量空间中。这里先将这个向量空间的符号定义明确,下一部分说明连续状态的映射时会更清晰。
使用 \(W\) 表示所有的token集合,使用 \(w_i\) 表示某一个token,使用 \(\mathcal{X} \in R^k\) 表示整个嵌入空间,使用 \(\gamma\) 表示词嵌入的映射,使用 \(x\) 表示某个token的词嵌入向量。定义了这些之后那么词嵌入的过程可以表示为: \(x_i=\gamma\left(w_i\right) \in R^k\)
连续状态映射到嵌入空间:
传感器会观测到很多连续状态(多模态),这些如果想要输入到模型中,也需要将其转换为向量,在本文中是将其转为与文本的token嵌入相同的向量空间中。
使用 \(\mathcal{O}\) 表示观测到的所有连续状态的集合,使用 \(O_j\) 表示某个观测到的具体的连续状态,训练编码器 \(\phi: \mathcal{O} \rightarrow \mathcal{X}^q\) 将 (连续) 观测空间 \(\mathcal{O}\) 映射为 \(\mathcal{X}\) 中 \(q\) 个向量序列,编码后的向量空间还是 \(\mathcal{X}\)。然后将这些向量与普通嵌入文本标记交错,以形成LLM的前缀。这意味着前缀中的每个向量 \(x_i\) 由单词标记嵌入器 \(\gamma\) 或编码器 \(\phi_i\) 构成:
连续状态的映射过程与文本token的映射过程的不同之处在于:一个token只映射为一个向量,一个连续状态可能需要映射为多个向量。比如观测到的一个连续状态可能是一段声音,只用一个向量不能很好的表示这段声音,就需要多个向量来表示。
定义了这些之后,那么文本和观测到的连续状态到嵌入向量的过程可以表示为:
\[x_i= \begin{cases}\gamma\left(w_i\right) & \text { if } i \text { is a text token } \\ \phi_j\left(O_j\right)_i & \text { if } i \text { is a vector from } O_j\end{cases}\]举个例子更好理解,比如原始数据为如下例子(本文中的传感器都是图像数据,没有音频数据,这里只是举个例子):
请提取录音中的内容<这里是一段录音内容>。
经过编码后的嵌入向量序列为: \(\left(x_1, x_2, \ldots, x_9, x_{10}, x_{11}, x_{12}, x_{13}\right)\) ,这个向量序列中各个向量的来源如下(假设这段录音内容被编码为了三个向量):
- $x_1$ : 来自于”请”
- $x_2:$ 来自于”提”
- …
- $x_9$ : 来自于”容”
- $x_{10}$ : 来自于<录音内容>
- $x_{11}$ : 来自于 <录音内容>
- $x_{12}$ : 来自于 <录音内容>
- $x_{13}$ : 来自于”。”
说明白了如何对连续状态进行编码,应该可以很容易的想到:虽然文本token和连续状态都被映射到了相同的向量空间中,但是做这个映射操作的模型肯定是不同的模型。关于token如何编码应该都很熟悉,需要说明如何对传感器观测到的信息做编码。
在机器人控制回路中具象输出
PaLM-E是一种生成模型,基于多模型句子作为输入生成文本。为了将模型的输出连接到实例。论文区分了两种情况。如果任务可以通过仅输出文本来完成,例如,在具体的问题回答或场景描述任务中,则模型的输出被直接认为是任务的解决方案。
或者,如果PaLM-E用于解决一个具体的计划或控制任务,它会生成一个文本来调节低级命令。特别是,假设可以使用一些(小的)词汇表来执行低级技能的策略,而PaLM-E的成功计划必须包含一系列此类技能。请注意,PaLM-E必须根据训练数据和提示自行确定哪些技能可用,并且不使用其他机制来约束或过滤其输出。尽管这些策略受语言限制,但它们无法解决长期任务或接受复杂指令。因此,PaLM-E被集成到一个控制回路中,在该回路中,机器人通过低级策略执行其预测决策,从而产生新的观察结果,如果需要,PaLME能够根据这些观察结果重新规划。从这个意义上讲,PaLME可以理解为一种高级策略,它对低级策略进行排序和控制。
传感器观测信息的编码策略
状态估计向量
状态向量,例如来自机器人或对象的状态估计,可能是输入到PaLM-e中最简单的。设 \(s \in \mathbb{R}^S\) 是描述场景中对象状态的向量,可以包含这些对象的姿势、大小、颜色等。这种输入数据可以直接转为向量,然后做一些归一化、对齐之类的操作就可以了。然后,经过一层MLP \(\phi_{\text {state }}\) 将状态 \(s\) 映射到语言嵌入空间。
Vision Transformer (ViT)
如果传感器的观测结果是图像类数据,一般来说图像类数据也是最常见的,直接使用比较成熟的 ViT 模型进行编码,在本文中 ViT 模型的尺寸选取 4B 和 22B 这两个模型。ViT \(\tilde{\phi}_{\mathrm{ViT}}\) 是一种将图像 \(I\) 映射为多个token嵌入 \(\tilde{x}_{1: m}=\tilde{\phi}_{\mathrm{ViT}}(I) \in \mathbb{R}^{m \times \tilde{k}}\) 的Transformer体系结构。另外,在ViT的基础上,又有人提出了 TokenLearner 结构,加上该结构之后,既降低了计算复杂度,又提升了指标,所以在本文中也会尝试这种结构。综上,本文在对图像类的输入进行编码时会尝试以下几种方案:
- ViT-4B
- ViT-22B
- ViT + TL(TokenLearner)
TokenLearner简介:由于图像类数据维度是2维的,如果直接使用像素点进行编码的话一张512*512的图片编码之后形成的token序列就变得非常长,而transformer架构对长序列的运算速度非常慢。针对这个问题,Google提出了TokenLearner方法,该方法能够自适应的学习输入图片或视频中的重要区域,然后主要对这些重要区域进行tokenize,以达到只需要少量的token就足以表征所有的视觉特征的目的。
需要注意的是,ViT嵌入的维数与语言模型的维数不一定相同。因此,将每个嵌入投影到 \(x_i=\phi_{\mathrm{ViT}}(I)_i=\psi\left(\tilde{\phi}_{\mathrm{ViT}}(I)_i\right)\) 中, \(\psi\) 是一个学习的仿射变换。
Projector
需要注意的是,提到的会使用 ViT 模型做图像数据的编码器,这里的 ViT 模型是之前已经预训练好的,那么没有办法保证 ViT 模型输出的向量维度与文本token的嵌入向量维度是相同的。
为了解决上述问题,就需要在编码器的后面有一个维度转换的模块,该模块的作用是将原始编码器输出的各种不同的维度都映射到相同的维度上。将该模块称为 Projector,使用符号 $\psi$ 表示。为了方便后续描述,对编码器(Encoder)也给一个符号,使用符号 $\phi$ 表示。有了这些符号之后,整个编码部分的公式如下:
\[x_i= \begin{cases}\text { embedding }\left(w_i\right) & \text { if position } i \text { is a text token } \\ \psi\left(\phi\left(O_j\right)\right)_i & \text { if position } i \text { is observation from sensor }\end{cases}\]所谓的 Projector 其实就是个全连接层,只要经过一个全连接,无论原来的向量维度是啥,都可以转换成自己想要的维度。最后,自己画了一下把上述几个部分都组合到一起的模型结构图,大致如下图所示 (下图中并不包含输出部分):
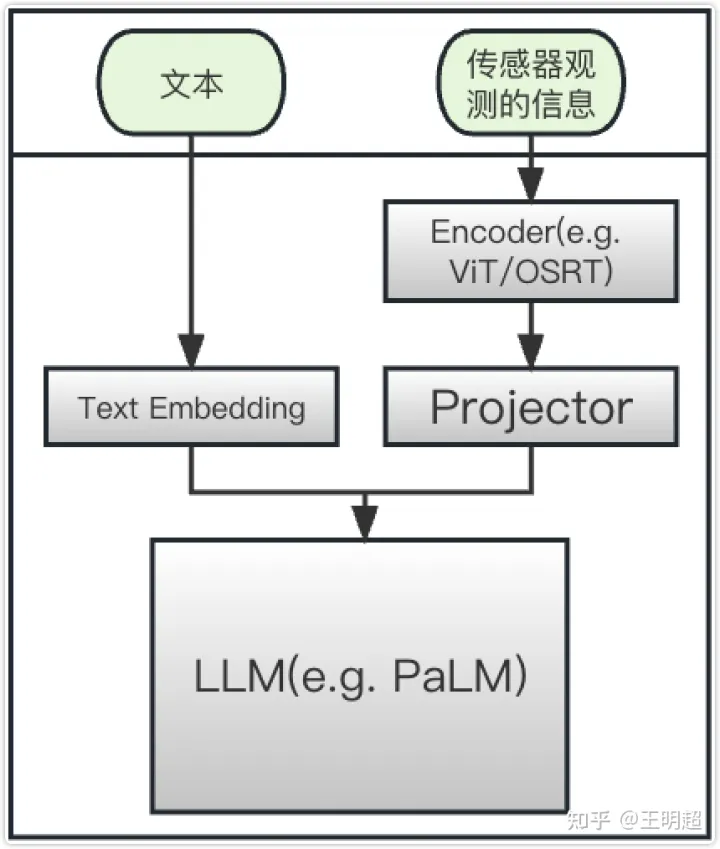
图像数据编码-高级版
在图像领域对于如何更好的编码图像数据,有不少的研究,本文中会使用以下两种技术:
- Object Centric Representations
- Object Scene Representation Transformer (OSRT)
这两种技术对数据的基本假设是相同的,他们都认为把一张图片按照网格均匀的划分开,然后对每个网格使用一个向量进行表示,这种方式是不太合理的。因为一张图片中可能会有多个物体(或者称为多个对象),直接对所有的图片都是用相同的网格划分,大概率可能把图片中的一个对象划分成了多个部分。而如果能够在划分时以图片中的每个对象为中心进行划分,编码出来的向量应该是更合理的。正是基于这个原因,提出了上述两种编码技术。
Entity Referrals实体转介
有些时候可以使用很简短的语言准确指向某一个物体,而有的时候则不能使用很简短的语言准确的指向某一个物体。举个例子来说明这个问题。比如当前桌面上有10个乐高模块,这10个模块的颜色各不相同,那么可以使用:”红色的块”、”蓝色的块”、”黄色的块”这种比较简洁的描述指明某一个具体的物体。但如果当前桌面上有10个颜色、形状都完全相同的10个乐高模块,那么如果想要指明某一个具体的块可能需要描述成:”最靠近左上角的那个块”、”从左往右数第3个,从上往下数第6个那个块”,这时描述起来就非常的长。
Entity Referrals 方法就是设计在描述非常长的时候如何进行编码。该方法的思路是:在数据的最前面部分添加上对每个具体物体的描述,这部分的模版为如下格式。在这个模版里面 Object_1 和 Object_j 分别指代一个具体的物品,<obj_1> 和 <obj_j> 分别是对这两个物品的详细描述。添加了这个模版之后,后面的文本中再需要使用某个物品时就直接使用 Object_j 来代指。
Object_1 is <obj_1>. ... Object_j is <obj_j>.
具体的例子如下(中文版):
物体1是位于桌面左上角的块。物体2是从左往右数第3个,从上往下数第6个那个块。请将物体1和物体2都移动到桌面右下角
训练策略
训练数据说明
使用 \(D\) 表示整个训练数据集,使用 \(i\) 表示第几条数据,使用 \(L\) 表示一条数据的长度,使用 \(u\) 表示一条数据中有多少个通过传感器观测到的连续状态,使用 \(n\) 表示一条数据中 prefix prompt 部分的长度。
定义了上述这些符号之后,整个数据集就可以表示为: \(D=\left\{\left(I_{1: u_i}^i, w_{1: L_i}^i, n_i\right)\right\}_{i=1}^N\) ,其中 \(I_{1: u_i}^i\) 表示第 \(i\) 条数据的总共 \(u_i\)个通过传感器观测到的连续状态, \(w_{1: L_i}^i\) 表示第 \(i\) 条数据的 \(L_i\)个token, \(n_i\) 表示第 \(i\) 条数据的prerix prompt的长度。
有一个需要注意的点是这里的 \(L_i\) 是一条数据的总长度,包含着连续状态编码成的向量。为了说明这一点,这里简述一下数据的构造过程。
每条数据以文本为主体,把图像、连续状态都串成一条数据,如下这种方式所示:
Q: What happened between <img 1> and <img 2>?
然后每个图像经过嵌入层之后会被转化为多少个向量是固定的,所以像上述数据只要给每个图像预留上对应个数的位置即可,会形成如下这种形式(这里假设每个图像都被编码为3个向量):
Q: What happened between <img1_vec1> <img1_vec2> <img1_vec3> and <img2_vec1> <img2_vec2> <img2_vec2> ?
输入模型时会使用对图像编码后的向量替换上述样例中预留的位置。
损失函数部分就是对从位置 \(n_i+1\) 开始到\(L_i\) 的这些位置使用交叉嫡损失。每条数据的前 \(n_i\) 个位置是prefix prompt,不计算损失。
模型冻结
本文中的整个模型系统可以分为三部分:
- Encoder 部分,用 \(\phi\) 表示,连续状态到嵌入空间;
- Projector 部分,用 \(\psi\) 表示,使ViT输出与文本嵌入维度相等;
- LLM 部分, 用 \(p_{L M}\) 表示,文本到嵌入空间;
在训练时不一定要这三部分的权重都同时更新,可以冻结其中的一部分,只训练另外部分的权重。 本文中实际采用的三个策略为:
- 三个部分都同时进行训练;
- 冻结 LLM 部分,训练 Encoder 部分和 Projector 部分;
- 冻结 LLM 部分和 Encoder 部分,只训练 Projector 部分;
采用上述后两种策略的理由:LLM部分采用PaLM作为基座,是已经在大量数据上做过预训练的,其本身可能就已经有着非常强的能力; Encoder部分也是类似的,比如采用ViT模型,那么该模型也是在大量图像数据上预训练过的; 在上述三部分中只有 \(\psi\) 是随机初始化的,这部分模型必须要重新训练。
测评任务
机器人任务
在本文中使用到的机器人环境有三个:
- 桌面操作环境(Tabletop Manipulation Environments)
- 移动操作环境(Mobile Manipulation Environments)
- 任务和运动规划(Task and Motion Planning, TAMP)
桌面操作环境
所谓的桌面操作环境就是在桌面上摆一些不同颜色、不同形状的物体,机器人按照输入的命令用机械臂移动这些物体。输入的命令比如为:”将全部红色块移动到左下角”,”将所有的块摆成一排”,”将所有的块按颜色分组”,等等。
移动操作环境
移动操作环境就是机器人是可移动的,不再固定在桌面上。官方提供的视频样例中的命令是:”帮我把抽屉里的薯片拿过来”,然后机器人会在厨房中自己去”找到抽屉”、”拉开抽屉”、”拿出薯片”、”合上抽屉”、”把薯片送回到人类手中”,这一系列工作都能够顺利完成。
任务和运动规划TAMP
TAMP是由四种 VQA(Visual Question Answering)问题和两种plan问题组成的。
所谓的 VQA 就是看图回答问题。比如在下图这个样例中,左侧的图片是模型的输入,右侧上方灰色的第一行也是模型的输入,右侧橙色背景的是模型的输出。

知道了什么是 VQA 问题之后,下面详细列一下本文实验中的4种 VQA 问题的类型,并且给每个问题类型一个例子:
- $q_1$ : 物品颜色问题。举例:给定一张图片。问:桌面上的物体是什么颜色? 答:桌面上的物体是黄色。
- $q_2$ : 物品-桌面位置关系问题。举例:给定一张图片。问:红色的物体在桌面的上方? 左方? 还是中心? 答: 红色的物体在桌面的中心。
- $q_3$ : 物品-物品位置关系问题。举例:给定一张图片。问:黄色的物体是在蓝色的物体的下方吗? 答: 黄色的物体不在蓝色的物体的下方。
- $q_4$ : 计划的可行性问题。举例:给定一张图片。问:先把蓝色的物体拿起来,然后把它堆放到黄色的物体上,然后能直接拿起黄色的物体吗? 答: 不能。
下面详细列一下2种 plan 问题的类型:
- $p_1$ : 抓取问题。举例:给定一张图片。问:如何抓取绿色的物体? 答:首先抓取黄色的物体并将其放到桌面上,然后抓取绿色的物体。
- $p_2$ : 堆叠问题。举例:给定一张图片。问:如何将白色的物体堆放到红色的物体上方? 答:首先抓取绿色的物体并将其放到桌面上,然后抓取白色的物体并将其堆放到红色的物体上方。
实验
桌面操作环境实验
数据集说明
该数据集是由 Lynch 等人在论文 Interactive language: Talking to robots in real time 中提出来的,称为 Language-Table 数据集。该数据集中的3个任务类型都是长期任务,所谓长期任务含义是:模型无法通过一步完成该任务,而是需要每次自己生成策略、执行相应的action,然后观察外界环境,再次自己生成策略、执行相应的action,直到观察外界环境满足了任务要求。整个过程如下图所示:
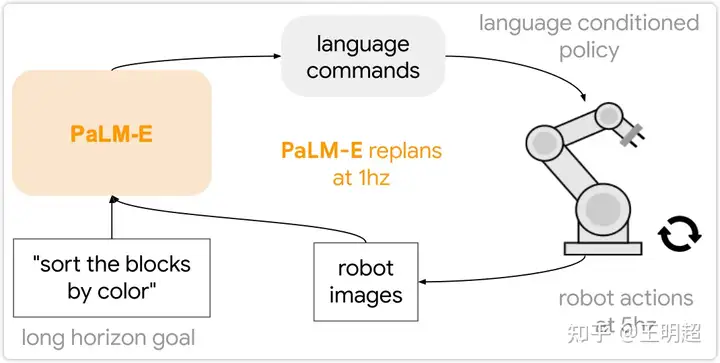
图中 “sort the blocks by color” 是一个长期任务:
- 模型 PaLM-E 每次的输入都是文本 “sort the blocks by color” 加上传感器拍摄的当前桌面的一张照片。
- 然后模型自己生成一个需要执行的策略,即上图中的 “language commands”,比如:将红色块移动到左侧。
- 机器人根据模型生成的策略执行相应的action。
- 机器人执行完action之后再次使用传感器拍摄当前桌面的照片,然后模型 PaLM-E 再次根据输入的文本 “sort the blocks by color” 加上新的照片生成要执行的策略,直到任务完成。
下面是该 Language-Table 数据集中的3个任务类型:
- Task1 问:将最靠近{某个方位,比如:右上角}的块,推到与它颜色相同的另一个块那里。
- Task2 问:将所有的块按照颜色分组,并将每组推到桌面的四个角上。
- Task3 问:将 {左侧/右侧} 的块推到一起,不要移动任何 {右侧/左侧} 的块。
参考文献
[1] PaLM-E: 具身多模态语言模型(Embodied Multimodal Language Model) - 知乎 (zhihu.com)
[2] 论文阅读-PaLM-E:多模态语言模型 - 知乎 (zhihu.com)
[3] 具身多模态大模型——Google PaLM-E论文解读 - 知乎 (zhihu.com)