Paper Read 7 - Attention Is All You Need
The emergence of LLM has advanced the field of robotics. These models can learn rich linguistic knowledge and semantic representations by being pre-trained on large-scale textual data. These models can then be fine-tuned to adapt to specific tasks or domains. Therefore, in this post, I am going to document my learning process of embodied intelligence. Since I only know about the robotics field before, and the main body of the paper is in the field of NLP, I decided to record in my native Chinese language in order to make it easier for me to understand.
This series is expected to consist of a relatively small number of posts, with the short-term end goal of sustaining my reading of the Google PaLM-E article.
Attention
详细课程地址:10.【李宏毅机器学习2021】自注意力机制 (Self-attention) (上)_哔哩哔哩_bilibili, 课程笔记Self-attention笔记。
简单的举例理解:注意力机制的本质Self-Attention Transformer QKV矩阵_哔哩哔哩_bilibili
Transformer
详细课程地址:13.【李宏毅机器学习2021】Transformer (下)_哔哩哔哩_bilibili,课程笔记Transformer笔记;
补充视频课程:李沐Transformer论文逐段精读【论文精读】_哔哩哔哩_bilibili
GPT
详细课程地址:李沐GPT,GPT-2,GPT-3 论文精读【论文精读】_哔哩哔哩_bilibili,课程笔记GPT1笔记,GPT2笔记,GPT3笔记
Concept
词向量
词向量是为了完成将词语转换成对应数值向量的表达形式,便于计算机读取和运算这一任务产生的名词概念。创建词向量的常用的方法有:独热编码和表示学习。
独热编
独热编码是一种用于将离散的词汇表示成二进制向量的方法,每个词汇对应一个唯一的向量,其中只有一个元素为1,其余元素为0。这个1位通常表示词汇在词汇表中的位置。独热编码的步骤如下:
构建词汇表:首先,需要构建一个包含文本数据中所有不同词汇的词汇表。每个词汇都被赋予一个唯一的整数标识,通常按照它们在词汇表中的顺序分配。
独热编码:对于每个词汇,将对应的整数标识转化为一个二进制向量,其中只有一个位置为1,而其他位置都为0。这个1位的位置表示词汇的标识。
举个例子,假设我们有一个包含4个词汇的词汇表:[“apple”, “banana”, “cherry”, “date”],那么独热编码后的向量如下:
“apple”:[1, 0, 0, 0] “banana”:[0, 1, 0, 0] “cherry”:[0, 0, 1, 0] “date”:[0, 0, 0, 1]
通用数学公式:v(“x”)∈R^N, 独热编码的优点是简单易懂,每个词汇都有唯一的编码。然而,它的缺点是无法捕捉单词间的相似性和语义关系,每个词都是独立的。除此之外,向量维度与词汇表大小相关,要为每个词创建一个维度,也导致了对于大型词汇表其向量会十分稀疏,只有一个位置为1其余都为0。
表示学习
表示学习是一项重要的自然语言处理(NLP)技术,旨在将词汇、短语或文本转换为稠密、低维的实值向量,以便于计算机更好地理解和处理文本数据。这一技术的核心思想是通过训练,将词汇表中的每个单词映射到一个固定长度的低维向量空间中,使得在这个向量空间中,相似的词汇具有相似的表示,从而捕获了词汇之间的语义信息。
大语言模型发展历程
第一阶段(2013-2017):前期探索与词嵌入
2013年,NLP领域迎来了重要的突破,词嵌入技术开始崭露头角。Google公司在2013年发布的Word2vec成为了时代的亮点,即上文中表示学习发放代表作。Word2vec的工作机制是将单词映射到低维向量空间,从而捕捉单词之间的语义关系。通俗地说,Word2vec能够快速将词语转换成模型所需要的向量形式,成为NLP领域强有力的工具,大大提升了NLP的效率,同时也标志着NLP从基于规则转向基于数据驱动。
第二阶段(2018-2019):BERT和自监督学习的崭露头角
BERT(Bidirectional Encoder Representations from Transformers)崭露头角:在2018年底,Google发布了BERT,这是一种双向自监督预训练模型,它引入了一种全新的范式,彻底改变了自然语言处理的方法。传统的自监督学习方法通常是单向的,而BERT则可以双向理解文本,这意味着它可以同时考虑一个词的上下文,大大提高了对上下文的理解。与此同时,OpenAI的GPT(Generative Pre-trained Transformer)模型也初露锋芒。虽然GPT采用了单向的自监督学习方法,但它拥有着巨大的生成能力,能够生成连贯、有逻辑的文本。这两个模型的出现使自监督学习成为自然语言处理的主流方法之一。
第三阶段(2020-2021):大规模模型和多模态任务
GPT-3的出现和参数规模的飞跃:2020年6月,OpenAI发布了GPT-3,这是一个巨大的预训练语言模型,具有数千亿的参数。GPT-3的出现引发了广泛的讨论和关注,它展示了前所未有的生成能力。模型库如Hugging Face的Transformers库得到了广泛的发展和推广。这些库提供了各种预训练语言模型的实现,使研究人员和开发者能够更轻松地访问和使用这些模型。这大大推动了模型的研究和应用。为了更好地适应特定领域的需求,研究人员开始开发专用的预训练模型。例如,BioBERT是专门用于生物医学领域的模型,LegalBERT则专注于法律领域。专用模型使得其在相应领域的任务上表现更为出色。除了文本处理,多模态任务也受到了广泛的关注。这一阶段见证了将文本与图像、音频等多种模态数据结合的研究,模型开始具备理解和处理多种类型数据的能力。这对于实现更复杂的自然语言处理任务和应用具有重要意义。
第四阶段(2022-至今):AIGC时代的到来
模型参数规模的进一步扩大:这一阶段模型参数规模的持续扩大,如GPT-4、Bard等已经拥有千亿乃至千万亿级别的参数。大规模模型的出现推动了NLP领域的进一步探索和创新。自回归架构成为主潮结构,这也使得其在生成式任务上表现出了更高的能力。
LLM基本结构
大多数LLM是基于Transformer架构,在大规模文本数据上进行预训练,然后微调至适用于任务要求的状态, 最后应用于各类NLP任务,如文本生成、文本理解、情感分析等。自 Bert作为双向语言模型,在大规模无标签语料库上使用专门设计的预练任务,使性能显著提升以来,预训练-微调便作为一个学习范式被遵循,科研人员将其引入不同的架构,比如bart、gpt等表现优异的模型中去。在本小节,将具体的介绍预训练和微调这两个概念。
预训练阶段工作步骤
LLM的预训练(Pretraining)是指在将模型用于特定任务之前,模型在大规模通用语料库上进行的初始训练阶段。模型在这个阶段会学习关于NLP的一般性知识,包括语法、语义、词汇等。这个过程通过自监督学习的方式进行。所以在这个过程中,语料库的规模和质量对于其获得强大的能力至关重要。
预训练的目标是让模型获得足够的语言理解能力,以便在后续的微调或特定任务中表现出色。一旦完成了预训练,模型可以通过微调(Fine-tuning)来针对具体任务进行进一步训练,以适应任务特定的数据和要求。
LLM的预训练过程的关键步骤如下:
1.数据收集:毋庸置疑,NLP类型的任务都是基于数据的。所以要准备好数据集。数据可以大体分为两类:通用文本数据,这类数据通常来源于网页、数据。规模较大,并且获取难度很低。专用文本数据则是根据任务目的去获取,比如代码或者论文等科学文本。
2.数据清洗和预处理:清洗过程包括但不限于去除不必要的格式、特殊字符,确保数据的质量和一致性。预处理数据时主要会对数据进行一下几个方面操作:1.质量过滤,删除语料库中的低质量数据。2.去重,在大量实验中发现,过多的重复数据也会影响语言模型的多样性,导致训练过程不稳定,从而影响模型的性能。3.隐私去除。4.分词。
3.构建模型架构:同普通的NLP任务一样,在数据准备好后,就会基于Transformers,选定合适的模型结构,以自监督学习方法进行训练。(自监督学习表示会根据输入文本预测另一部分内容)
4.参数调整:在预训练过程中,需要调整模型的超参数,如学习率、批次大小、训练轮数等,以便取得最佳的性能。
5.保存和部署预训练模型:以模型参数的方式,保存预训练模型权重,以供下游任务使用。
预训练阶段模型结构
除了编码器(encoder)、解码器(decoder)、(编码器-解码器)encoder-decoder模型以外,常见的预训练模型结构还有:
Causal Language Modeling(因果语言模型)
CLM(Contrastive Language Modeling)是一种采用单向注意力掩码自监督学习方法,核心思想是通过生成文本的方式来学习语言表示。这种思想确保每个输入标记只关注过去标记和它本身。在这种方法中,模型在生成文本时只关注前面的文本,而不考虑后面的文本,因此这种方法生成的文本是因果的(causal)。
在传统的自监督学习方法中,文本被编码成一个上下文向量,然后被用于计算相似度或者生成文本。在CLM中,则使用对角掩蔽矩阵来保证各token只能看到它之前的token。具体来说,对角掩蔽矩阵的对角线元素为1,其他元素为负无穷,这使得每个token只能看到它前面的token。这使得CLM能够生成因果文本,因为它只能根据之前的token来生成下一个token,而忽略后面的token。
CLM是一种基于生成的自监督学习方法。在生成文本时,模型从当前时刻的隐藏态(hidden state)中采样当前时刻的token,然后将该token加入训练集中。由于生成的token是因果的,因此训练集也被约束为因果,也就是说,如果输入一个之前的token,那么生成的下一个token必须依赖于这个token。这个约束使得模型能够学习到有效的语言表示。迄今为止,因果解码器已被广泛采用为各种现有大语言模型的体系结构,例如GPT 、BLOOM 和 Gopher 。
Causal LM只涉及到Encoder-Decoder中的Decoder部分,采用Auto Regressive模式,直白地说,就是根据历史的token来预测下一个token,也是在Attention Mask这里做的手脚。
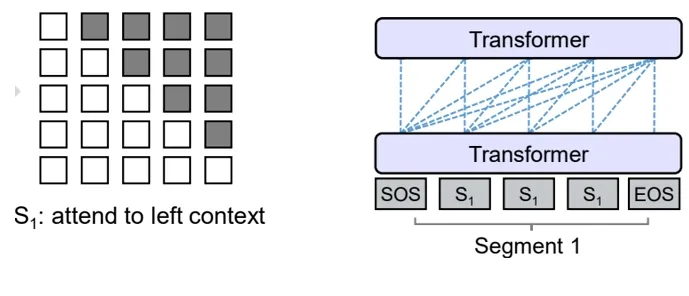
Prefix Language Model(前缀语言模型)
它可以看作是Encoder-Decoder模型的一种变体。 在传统的Encoder-Decoder模型中,Encoder用于将输入序列编码为固定长度的向量表示,其为 AE模式即双向注意力机制,而Decoder则使用单向注意力机制,来使这个向量生成输出序列。可以说它修正了CLM的掩码机制,使其前缀标记执行的是双向注意力机制,但是生成的标记只是单向注意力。
而在Prefix LM中,前缀(prefix)部分充当了Encoder的角色,它包含了输入信息或上下文。模型根据前缀生成连续的文本,这一过程类似于Decoder的工作,但在这里没有明确的分隔符来标识输入和输出序列,因为他们共用一个transformer blocks,在Transformer内部通过Attention Mask机制来实现。。可以将Prefix LM视为Encoder-Decoder模型的一种扩展,其中Encoder和Decoder之间没有明确的边界,允许更加灵活的文本生成。
与标准Encoder-Decoder类似,Prefix LM在Encoder部分采用Auto Encoding (AE-自编码)模式,即前缀序列中任意两个token都相互可见,而Decoder部分采用Auto Regressive (AR-自回归)模式,即待生成的token可以看到Encoder侧所有token(包括上下文)和Decoder侧已经生成的token,但不能看未来尚未产生的token。
下面的图很形象地解释了Prefix LM的Attention Mask机制(左)及流转过程(右)。
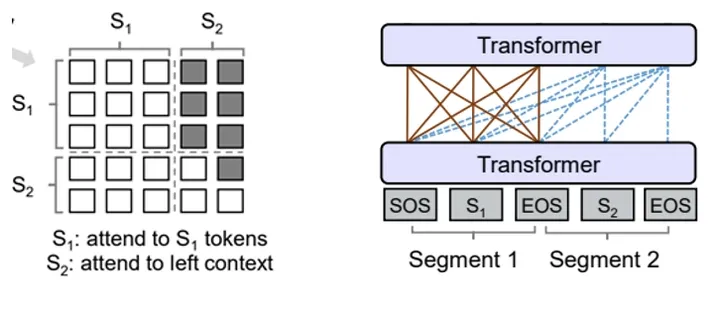
Premuted Languge Model(排列语言模型)
PLM 的核心思想是通过对输入文本进行排列重组(置换)来训练模型,从而使其具备更好的序列建模能力。同前缀语言模型,它也是采用单个 Transformer 模型作为主干结构,同时在训练方法上采用了一种独特的方式,将形式看似是自回归(AR)的输入过程与实际上是自编码(AE)的方法相结合。Premuted LM 的外在表现形式是按照自回归(AR)方式生成文本,而 AE 通常直接编码和解码输入数据,没有显式的生成过程。但它在内部使用了 Attention Mask,将上下文信息编码到每个位置,然后根据上下文生成输出。这是一种同时结合了自回归(AR)和自编码(AE)特性的方法。而 AE 更注重数据的压缩和重构,不一定需要生成文本。Premuted LM 更适合自然语言生成任务,如文本生成、翻译等,因为它在外观上类似于AR模型。而 AE 通常用于数据重构、特征学习等领域。
总的来说,PLM 是一种将自回归和自编码的思想结合在一起的预训练模型,它在外观上看似AR,但内部实际上采用了AE的方法,从而在不同的应用场景中具有独特的优势。
Fine-tuning(微调)
本文第一节中介绍了预训练其实就是利用海量数据训练一份模型参数保存下来,这些参数将被应用于微调。预训练+微调的工作模式使得我们完成任务的时候,无须在从头构建一个新的模型。 值得注意的是Fine-tuning是一个通用概念,不同的任务采用不同的微调方法,比如Instruction Tuning、Task-Specific Fine-tuning、Domain Adaptation、Prompt Engineering等等,但无论选择哪种方法,其流程都大体如下:
1.选择预训练模型:根据任务选择一个在大规模数据上训练过的预训练模型。
2.准备数据:准备特定任务的训练数据集。这个数据集通常比预训练模型的数据集小得多,因为微调的目标是调整模型以适应新数据。
3.定义任务:为任务定义输入和输出。例如,对于文本分类,输入可以是文本,输出可以是类别标签;对于图像分割,输入可以是图像,输出可以是每个像素的标签。
4.微调模型:最后,使用准备好的数据集,将预训练模型的权重微调,以最小化任务特定的损失函数。
进一步细化介绍下微调的相关概念以及步骤:
- Tokenizer:这个组件负责数据预处理,将自然语言文本转换为适用于模型输入的形式。
- Datasets:用于训练模型的数据集,可以直接从社区获取各种数据集,方便快捷。
- Model:这是对PyTorch模型的封装,专门用于更好地支持预训练模型的使用。
- Evaluate:评估函数,用来对模型的输出结果进行全面的评估和分析。
- Trainer:训练器,可以在其中配置各种模型参数,以便快速启动模型训练流程。
- Pipeline:模型推理的必备工具,快速验证和检查模型的输出结果。
总结一下:导入想要应用的包->加载想要训练的数据集->(划分数据集)->预处理数据集->创建model->(设置评估函数)->创建trainer->配置trainer参数->模型训练
Task-specific Fine-tuning(任务特定微调)
Task-specific Fine-tuning 是Fine-tuning的一种具体应用,它指的是将模型微调以适应特定任务。这个任务可以是任何NLP类型任务,包括文本分类、文本生成、问答等。当在Fine-tuning中使用特定任务的数据集和损失函数时,就可以说我们正在进行 Task-specific Fine-tuning。
让我们通过一个实际的例子来解释Task-specific Fine-tuning(任务特定微调):
假设有一个预训练语言模型以及一个NER(命名实体识别)任务,任务是从文本中识别出人名、地名、组织名等命名实体。
以下是任务特定微调的步骤:
- 预训练模型:首先,准备一个在大规模文本数据上进行了预训练的模型,该模型具备了一定的自然语言理解能力。
- 数据准备:为了执行NER任务,准备一个任务特定的数据集,其中包含了包含命名实体标注的文本样本。这个数据集是特定任务的数据,通常包括训练集和验证集。
- 任务定义:定义这个任务的输入和输出格式。在NER任务中,输入是文本序列,输出是相应文本序列中每个词对应的命名实体标签(如人名、地名、组织名等)
- 微调模型:使用预训练模型,将其权重微调到NER任务上。
- 评估和使用:一旦模型经过微调,可以在验证集上评估其性能。当性能满足要求,就可以将该模型部署到实际应用中,用于识别文本中的命名实体。
在这个例子中,Task-specific Fine-tuning 是将通用预训练模型(BERT)微调为特定任务(NER)的过程。通过提供任务特定的数据集和相应的标签,可以使模型学会在文本中识别命名实体。
Instruction Tuning(指令微调)
Instruction tuning是fine-tuning 的一种方式,通过提供特定领域的指令和数据来调整模型,以适应该领域的文本和任务要求。依旧是通过一个实际的例子来解释Instruction Tuning(指令微调):
假设一家律师事务所需要频繁地生成法律文件,包括合同、法律建议和法庭文件。想要利用AI来自动化这个过程,以节省时间和提高效率。
- 选择预训练模型:首先,选择一个在大量法律类型数据上进行了预训练的语言模型。
- 准备数据:为了生成法律文件,准备一个任务特定的数据集,其中包括了符合事务所特征的常用法律术语、法规和法律文件的示例。这个数据集将被用于Instruction Tuning。
- 定义任务:生成特定类型的法律文件。例如,你可能提供以下指令:“生成一份租赁合同,包括租金、租赁期限和各方信息。”
- Instruction Tuning:现在,将选择的预训练模型进行Instruction Tuning。在这个过程中,将使用准备好的任务特定数据集和任务指令来微调模型。模型会学会理解指令,并生成符合法律要求的合同文本。
- 生成法律文件:当模型经过Instruction Tuning,就可以将指定的任务指令提供给模型,它会生成相应的法律文件。例如,它可以生成一份租赁合同,其中包含了正确的租金、租赁期限和各方信息,并且完全符合法律要求。
在这个例子中,Instruction Tuning将通用的预训练语言模型调整为法律领域的专用生成器,它能够根据指令生成特定类型的法律文件。
指令微调对于预训练模型的效果提升作用不容忽视,主要有两个方面的影响:从性能上看,此种微调方式挖掘了大语言模型的能力,在多个语言模型上研究后发现,各种规模的都会在指令微调中受益。第二个方面则是使得任务泛化性能力大大增强,进行了指令微调的大模型,对于未曾见过的任务也能实现卓越的性能表现。
Domain Adaptation(领域适应)
Domain Adaptation(领域适应)是一种将模型从一个领域适应到另一个领域的方法。与Instruction Tuning类似,它可以利用所涉及领域的特定数据来微调模型,以提高在特定领域任务中的性能。
假设有一个源领域的模型应用场景为:针对某社交媒体类软件上的评论进行情感分析,该模型在通用社交媒体评论数据上进行了Fine-tuning,以执行情感分析任务。
现在,如果想将这个情感分析模型用于某一特定行业,比如医疗行业。那么在医疗领域的评论,就及有可能包含特定的医学术语,与源领域中通用社交媒体评论有所不同。可以理解为这是一个目标领域。
为了使通用情感分析模型更加适应于医疗保健领域,则可以执行以下步骤:
Fine-tuning(微调):首先,已经在通用社交媒体评论数据上对模型进行了Fine-tuning,以执行情感分析任务,这里不再赘述。
Domain Adaptation(领域适应):将模型从源领域(社交媒体评论)适应到目标领域(医疗保健评论)。在这个过程中,会使用医疗保健领域的评论数据,同时结合源领域的数据,以微调模型的参数。这个微调过程涉及到将模型适应医疗保健领域的特定情感分析任务。
通过Domain Adaptation,情感分析模型现在可以更好地理解医疗保健评论中的医学术语和情感内容,并执行情感分析任务。模型的性能在医疗保健领域得到了提高,同时仍然能够在通用社交媒体评论上执行情感分析。
Layer-wise Fine-tuning(逐层微调)
Layer-wise Fine-tuning 是一种微调方法,通过这种方法,我们可以对模型进行精细的调整,而不必调整整个模型。这种方法通常用于控制模型的复杂性,使其更适应特定任务。
假设现在需要处理图像分类任务,有一个预训练模型,这个模型有多个卷积层和全连接层。在微调时,通常只对最后一个卷积层进行微调,而不是整个网络,这就是Layer-wise Fine-tuning。
为什么要这样做呢?因为往往都是在最后一个卷积层通常包含了一些高级特征,例如物体的形状和色彩等信息,这些特征对于特定的图像分类任务可能非常有用。所以,只要通过微调最后一层,就可以在保留模型底层特征提取能力的同时,将模型调整得更适合我们的任务。
这个过程就好像是在用一块精准的刀子对模型进行微调,专注于任务所需的部分,而不是对整个模型进行全面的改动。
Multi-Task Learning(多任务学习)
顾名思义,Multi-Task Learning就是在一个模型中同时处理多个相关任务。这种方法有几个好处:一是通过共享特征表示,使得模型更好的泛化到新数据和新任务上;二是因为此类微调可以将不同任务的信息结合起来,从而帮助了模型在有限的数据中学习更多的知识;三是降低过拟合,当任务数据较少时,多任务学习可以通过共享知识来减轻过拟合问题。
假设我们正在开发一个AI助理,它需要具备多种文本能力,比如要能够进行文本分类,文本理解或者是命名实体识别。在传统方法中,我们可能需要为每个任务训练一个单独的模型。但是,使用Multi-Task Learning,我们可以在同一个模型中同时训练多个任务。
在这个模型中,底层的特征提取层会从文本中提取共享的信息,例如语法、词义等。然后,每个任务都有自己的输出层,用于执行文本分类或命名实体识别。这使得模型能够更好地理解文本中的多个信息,并在多个任务之间共享知识。
通过这种方式,Multi-Task Learning 允许我们在单个模型中同时解决多个相关任务,从而提高了模型的性能和通用性。
Prompt Engineering(提示设计)
Prompt engineering通常是在微调(Fine-tuning)的上下文中使用的一种技术,通过设计或选择任务相关的提示来引导预训练语言模型(如GPT-3、BERT)执行特定的任务或生成特定类型的文本。这个技术的目的是通过巧妙构prompt提示语,来影响模型的行为,使其在特定任务上表现出色。
假设我们有一个预训练语 言模型,希望使用它来执行情感分析任务,即确定一段文本的情感是积极的、消极的还是中性的。我们可以使用Prompt Engineering来设计提示,以引导模型执行这个任务。
示例:请分析以下文本的情感:[文本]
在这个提示中,”[文本]”是一个占位符,我们将实际的文本插入其中。模型接收到这个提示后,会根据提示的要求生成相应的情感分析结果。例如,如果我们将一段文本:”这部电影太精彩了!” 插入占位符,模型可能会生成结果:”积极情感”。
Prompt Engineering帮助我们引导模型执行情感分析任务,这种方法非常灵活,可以根据不同的情境和任务需求设计不同的提示。
Note
RNN
对于处理输入、输出不定长且存在上下文依赖的序列数据,类似DNN、CNN网络其效率较低,且无法解决依赖问题。对此我们需引入循环神经网络。(RNN, Recurrent Neural Network)
RNN的核心思想即是将数据按时间轴展开,每一时刻数据均对应相同的神经单元,且上一时刻的结果能传递至下一时刻。至此便解决了输入输出变长且存在上下文依赖的问题。
循环神经网络可以看做在做“加法”操作,即通过加法中的进位操作,将上一时刻的信息或结果传递至下一时刻,如下所示:
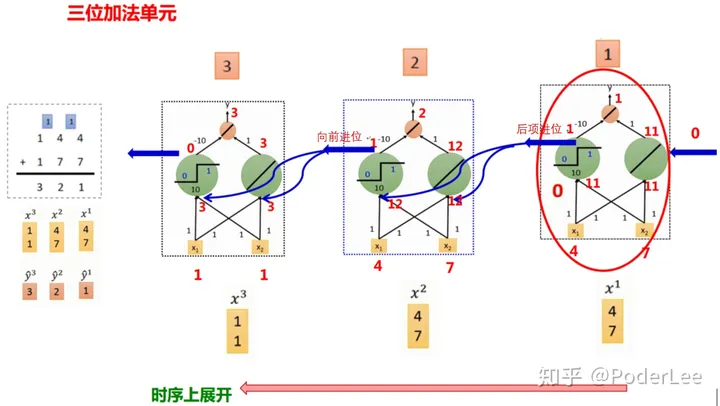
RNN单元结构及其在时序上的展开如下图所示:
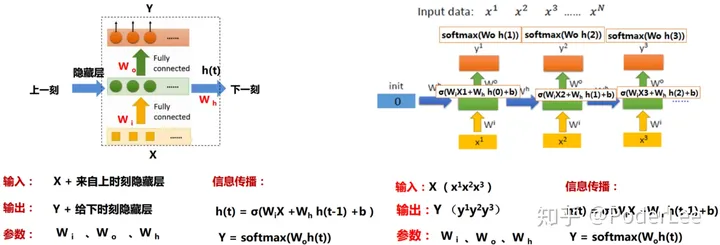
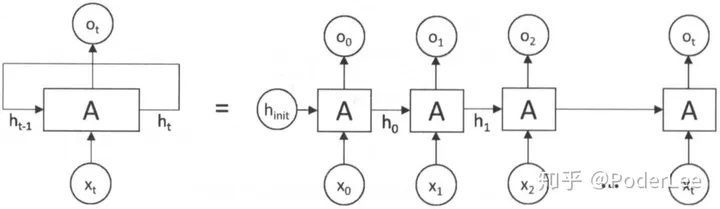
可以看出RNN网络的输入输出均为序列数据,其网络结构本质上是一个小的全连接循环神经网络,只不过在训练时按时序张开。
RNN网络前向传播过程如下:
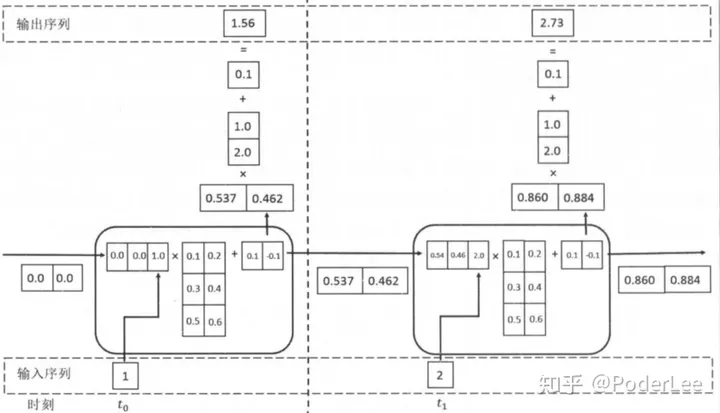
RNN网络误差反向传播过程如下:
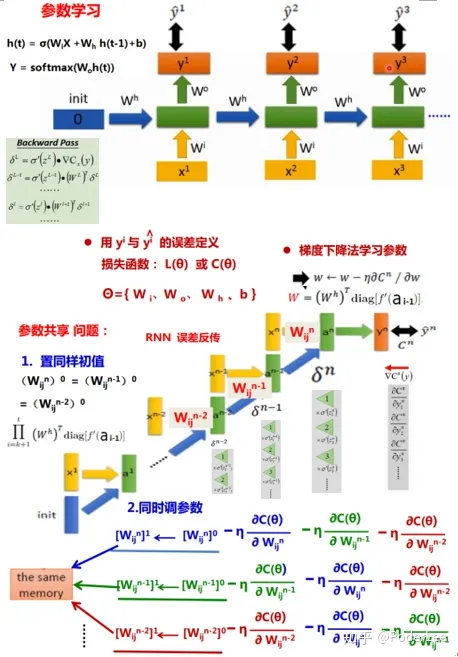
RNN的训练过程是子网络沿时间轴的展开,其本质上仍在训练同一个子网络,因此在每次梯度下降时我们需要对同一个子网络的参数进行更新。常见的做法是在每一次参数的调整使均指向同一内存地址。
RNN存在优化困难的问题
训练时间长,梯度消失 \(\prod_{i=k+1}^t\left(W^h\right)^T \operatorname{diag}\left[f^{\prime}\left(a_{i-1}\right)\right]<1\) ,出现情况较少,但对优化过程影响很大
梯度爆炸问题 \(\prod_{i=k+1}^t\left(W^h\right)^T \operatorname{diag}\left[f^{\prime}\left(a_{i-1}\right)\right]>1\) ,大部分情况
对于梯度消失问题,由于相互作用的梯度呈指数减少,因此长期依赖信号将会变得非常微弱,而容易受到短期信号波动的影响,而对于梯度爆炸问题,我们一般采取梯度截断的方法。目前解决RNN网络长期依赖问题更为普遍的做法是引入LSTM单元。
LSTM
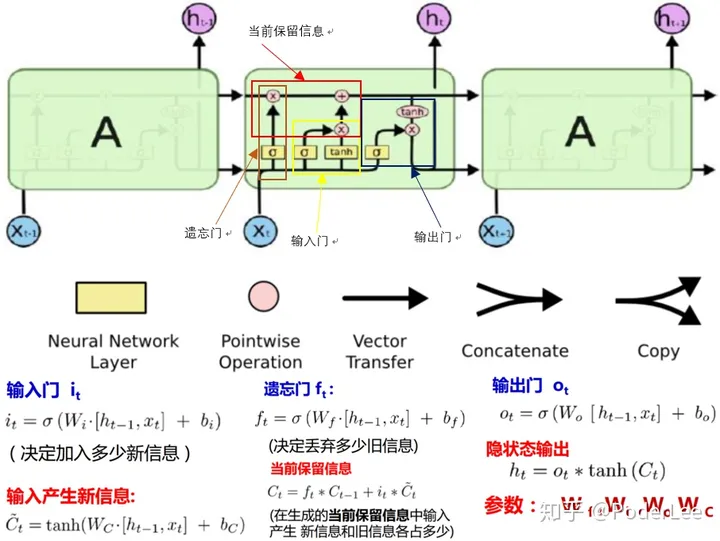
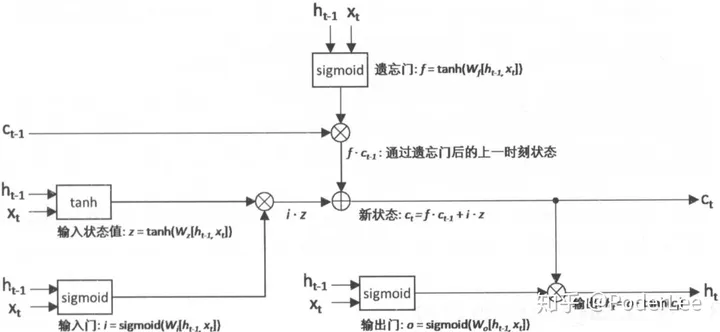
LSTM与单一tanh循环体结构不同,其拥有三个特殊的“门”结构,它是一种特殊的循环体网络。
LSTM单元不仅接受此时刻的输入数据 \(x_t\) 和上一时刻的状态信息 \(h_{t-1}\) ,其还需建立一个机制能保留前面远处结点信息不会被丟失。具体操作是通过设计“门”结构实现保留信息和选择信息功能 (遗忘门、输入门),每个门结构由一个sigmoid层和一个poinewise操作 (按位乘法操作) 构成。其中sigmoid作为激活函数的全连接神经网络层会输出一个0到1之间的数值,描述当前输入有多少信息量可以通过这个结构,其功能就类似于一扇门。
对于遗忘门,其作用是让循环神经网络 “忘记”之前没有用的信息。遗忘门会根据当前的输入 $x_t$和上一时刻输出 $h_{t-1}$ 决定哪一部分记忆需要被遗忘。假设状态 $c$ 的维度为 $n$ ,“遗忘门” 会根据当前的输入 $x_t$ 和上一时刻输出 $h_{t-1}$ 计算一个维度为 $n$ 的向量 $f=\operatorname{sigmoid}\left(W_1 x+W_2 h\right)$ ,其在每一维度上的值都被压缩在 $(0,1)$ 范围内。最后将上一时刻的状态 $c_{t-1}$ 与 $f$ 向量按位相乘,在 $f$ 取值接近0的维度上的信息就会被 “遗忘”,而 $f$ 取值接近1的维度上的信息将会被保留
在循环神经网络 “忘记”了部分之前的状态后,它还需要从当前的输入补充最新的记忆。这个过程就是通过输入门完成的。输入门会根据 $x_1$ 和 $h_{t-1}$ 决定哪些信息加入到状态 $c_{t-1}$ 中生成新的状态 $c_t$ 。输入门和需要写入的新状态均是由 $x_t$ 和 $h_{t-1}$ 计算产生。
LSTM结构在计算得到新的状态 $c_t$ 后需要产生当前时刻的输出,这个过程是通过输出门完成的。输出门将根据最新的状态 $c_t$ 、上一时刻的输出 $h_{t-1}$ 和当前的输入 $x_t$ 来决定该时刻的输出 $h_t$。通过遗忘门和输入门的操作循环神经网络LSTM可以更加有效地决定哪些序列信息应该被遗忘,而哪些序列信息需要长期保留,其结构如下图所示:
GRU
LSTM结构如上图所示,可以看出其结构较为复杂,这也引起了研究人员的思考:LSTM结构中到底那一部分是必须的?还可以设计哪些结构允许网络动态的控制时间尺度和不同单元的遗忘行为?对此设计GRU单元(Gated recurrent unit),以简化LSTM,如下所示:
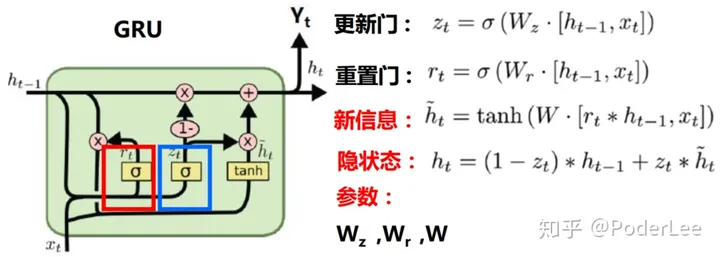
如上图所示,GRU与LSTM最大的区别是其将输入门和遗忘门合并为更新门(更新门决定隐状态保留放弃部分)。
Encoder-Decoder
虽然LSTM确实能够解决序列的长期依赖问题,但是对于很长的序列(长度超过30),LSTM效果也难以让人满意,这时我们需要探索一种更有效的方法,即注意力机制(attention mechanism)。在介绍注意力机制前,我们先了解一种常用的框架:Encoder-Decoder框架。
在上文的讨论中,我们均考虑的是输入输出序列等长的问题,然而在实际中却大量存在输入输出序列长度不等的情况,如机器翻译、语音识别、问答系统等。这时我们便需要设计一种映射可变长序列至另一个可变长序列的RNN网络结构,Encoder-Decoder框架呼之欲出。
Encoder-Decoder框架是机器翻译模型的产物,其于2014年在Seq2Seq循环神经网络中首次提出。Seq2Seq模型的基本思想非常简单一一使用一个循环神经网络读取输入句子,将整个句子的信息压缩到一个固定维度(注意是固定维度,下文的注意力集中机制将在此做文章)的编码中;再使用另一个循环神经网络读取这个编码,将其解压为目标语言的一个句子。这两个循环神经网络分别称为编码器(Encoder)和解码器(Decoder),这就是 encoder-decoder框架的由来。如下图所示:
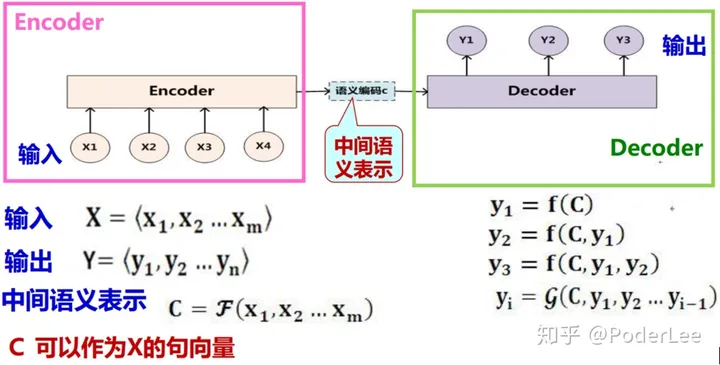
Decoder:根据 x 的中间语义表示 c 和已经生成的 \(y_1, y_2, \ldots, y_{i-1}\) 来生成 i 时刻的 \(y_i, y_i=g\left(c, y_1, y_2, \ldots, y_{i-1}\right)\) 。解码器部分的结构与一般的语言模型几乎完全相同: 输入为单词的词向量,输出为softmax层产生的单词概率,损失函数为log perplexity。事实上,解码器可以理解为一个以输入编码为前提的语言模型。
Encoder:对输入序列 x 进行编码,通过非线性变换转化为中间语义表示 \(c, c=F\left(x_1, x_2, \ldots, x_m\right)\) 。编码器部分网络结构更为简单。它与解码器一样拥有词向量层和循环神经网络,但是由于在编码阶段并未输出最终结果,因此不需要softmax层。
Encoder-Decoder是一个十分通用的计算框架。此外,Encoder-Decoder框架其本质是实现直观表示(例如词序列或图像)和语义表示之间来回映射。故通过该框架我们可以使用来自一种模态数据的编码器输出作为用于另一模态的解码器输入,以实现将一种模态转换到另一种模态的系统。正因为这个强大的功能,Encoder_Decoder框架以应用于机器翻译,图像生成标题等众多任务中。
Attention Mechanism
Attention Mechanism最早引入至自然语言中是为解决机器翻译中随句子长度增加其性能显著下降的问题,现已广泛应用于各类序列数据的处理中。
机器翻译问题本质上可以看做是编码解码问题,即将句子编码为向量然后解码为翻译内容。早期的处理方法一般是将句子拆分为一些小的片段分别单独进行处理,深度学习通过构建一个大型的神经网络对同时考虑整个句子内容,然后给出翻译结果。其网络结构主要包括编码和解码两个部分,如双向RNN网络。
编码器将一个句子编码为固定长度的向量,而解码器则负责进行解码操作。然而实验表明这种做法随着句子长度的增加,其性能将急剧恶化,这主要是因为用固定长度的向量去概括长句子的所有语义细节十分困难。
为克服这一问题,Neutral Machine Translation by Jointly Learning to Align and Translate文中提出每次读取整个句子或段落,通过自适应的选择编码向量的部分相关语义细节片段进行解码翻译的方案。即对于整个句子,每次选择相关语义信息最集中的部分同时考虑上下文信息和相关的目标词出现概率进行翻译。注意力集中机制(Attention Mechanism)(本质上是加权平均形成上下文向量),这在长句子的处理中得到了广泛的应用。
注意力机制的主要亮点在于对于seq2seq模型中编码器将整个句子压缩为一个固定长度的向量 $c$ ,而当句子较长时其很难保存足够的语义信息,而Attention允许解码器根据当前不同的翻译内容,查阅输入句子的部分不同的单词或片段,以提高每个词或者片段的翻译精确度。
一个自我关注模块接受n个输入并返回n个输出。这个模块中发生了什么?用外行人的话来说,自我注意机制允许输入相互作用(“自我”),并发现他们应该更关注谁(“注意”)。这些输出是这些交互作用和注意力分数的总和。
具体做法为解码器在每一步的解码过程中,将查询编码器的隐藏状态。对于整个输入序列计算每一位置 (每一片段)与当前翻译内容的相关程度,即权重。再根据这个权重对各输入位置的隐藏状态进行加权平均得到 “context” 向量 (Encoder-Decoder框架向量 $c$ ),该结果包含了与当前翻译内容最相关的原文信息。同时在解码下一个单词时,将context作为额外信息输入至RNN中,这样网络可以时刻读取原文中最相关的信息,而不必完全依赖于上一时刻的隐藏状态。Attention本质上是通过加权平均,计算可变的上下文向量 $c$ 。
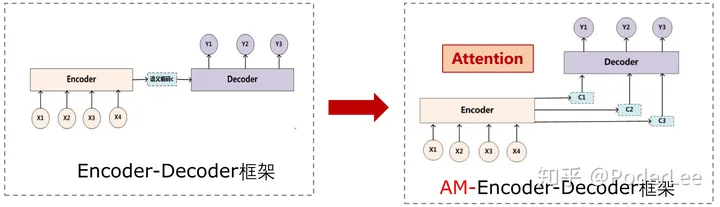
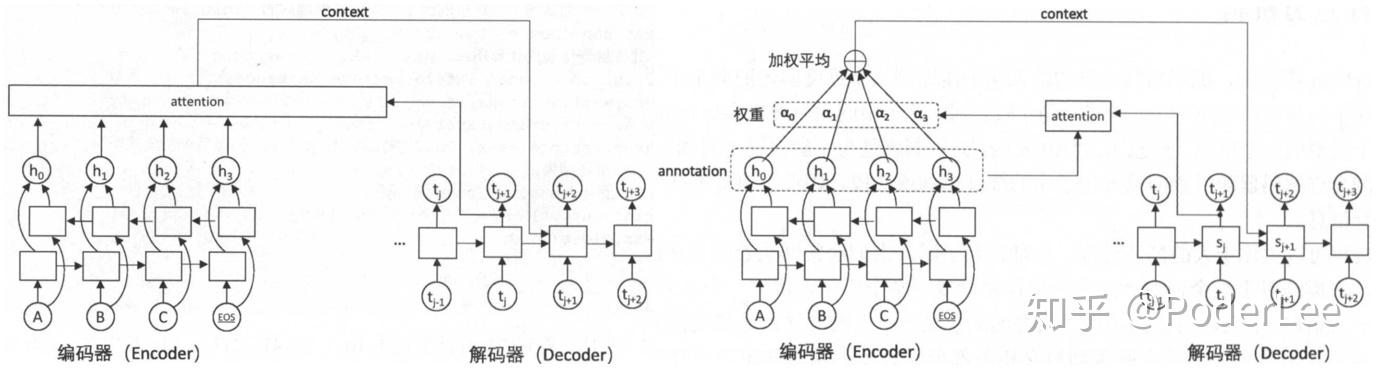
对比Attention和seq2seq可以发现主要有两点差别:
(1) Attention编码器采用了一个双向循环网络。虽然seq2seq模型也可以使用双向循环网络作为编码器,但是在注意力机制中,这一设计必不可少。其主要是因为解码器通过注意力查询一个单词时,通常需要知道该单词周围的部分信息,而双向RNN通常能实现这一要求。
(2) Attention中取消了编码器和解码器之间的连接,解码器完全依赖于注意力机制获取原文信息。取消这一连接使得编码器和解码器可以自由选择模型。例如它们可以选择不同层数、不同维度、不同结构的循环神经网络,可以在编码器中使用双向LSTM,而在解码器使用单向LSTM,甚至可以用卷积网络作为编码器、用循环神经网络作为解码器等。
Transformer
为实现并行
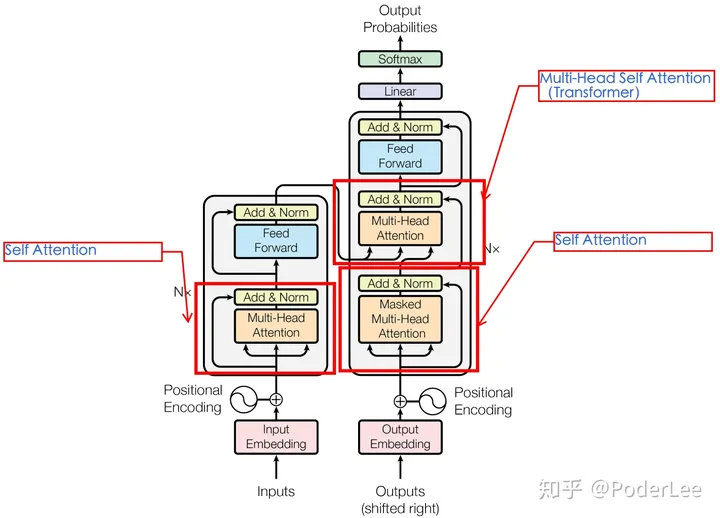
上图为Transformer的整体结构框架,接下来我们进行详细介绍。
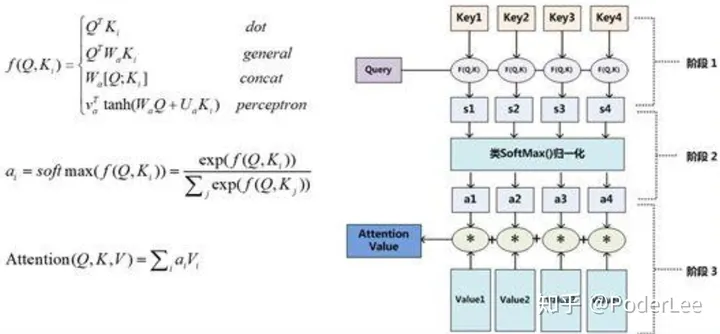
\[\begin{gathered} \operatorname{Attention}(Q, K, V)=\operatorname{softmax}\left(\frac{Q K^T}{\sqrt{d_k}}\right) V, Q \rightarrow R^{n \times d k}, K \rightarrow R^{m \times d k}, V \\ \rightarrow R^{m \times d v} \end{gathered}\]上式中, \(\sqrt{d_k}\) 为scale factor主要用于限制函数内积的大小,以防止其进入Softmax函数的饱和区网络收敛较慢。
(1) Self-Attention
当我们将Q, K, V均替换为输入序列X时,其即为Self-Attention机制。我们可以看出Self-Attention其本质是在寻找序列内部的联系,可以将其理解为在进行句法、语义分析。此外Self-Attention可以摆脱句子长度的限制,无视词与词之间的距离,直接计算依赖关系,从而学习一个句子的内部结构。
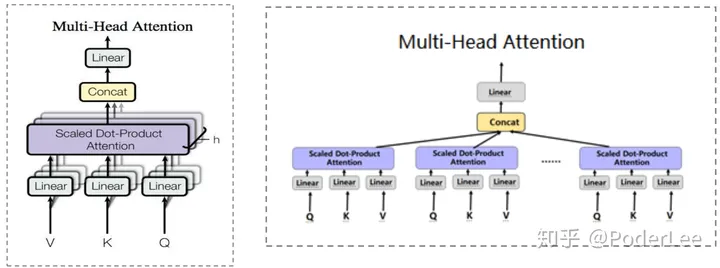
(2) Multi-Head Attention
Multi-Head Attention其本质为多个独立、平行的Attention concat而来,通过多个独立的Attention的简单拼接我们可以获得不同子空间上的相关信息。
GPT
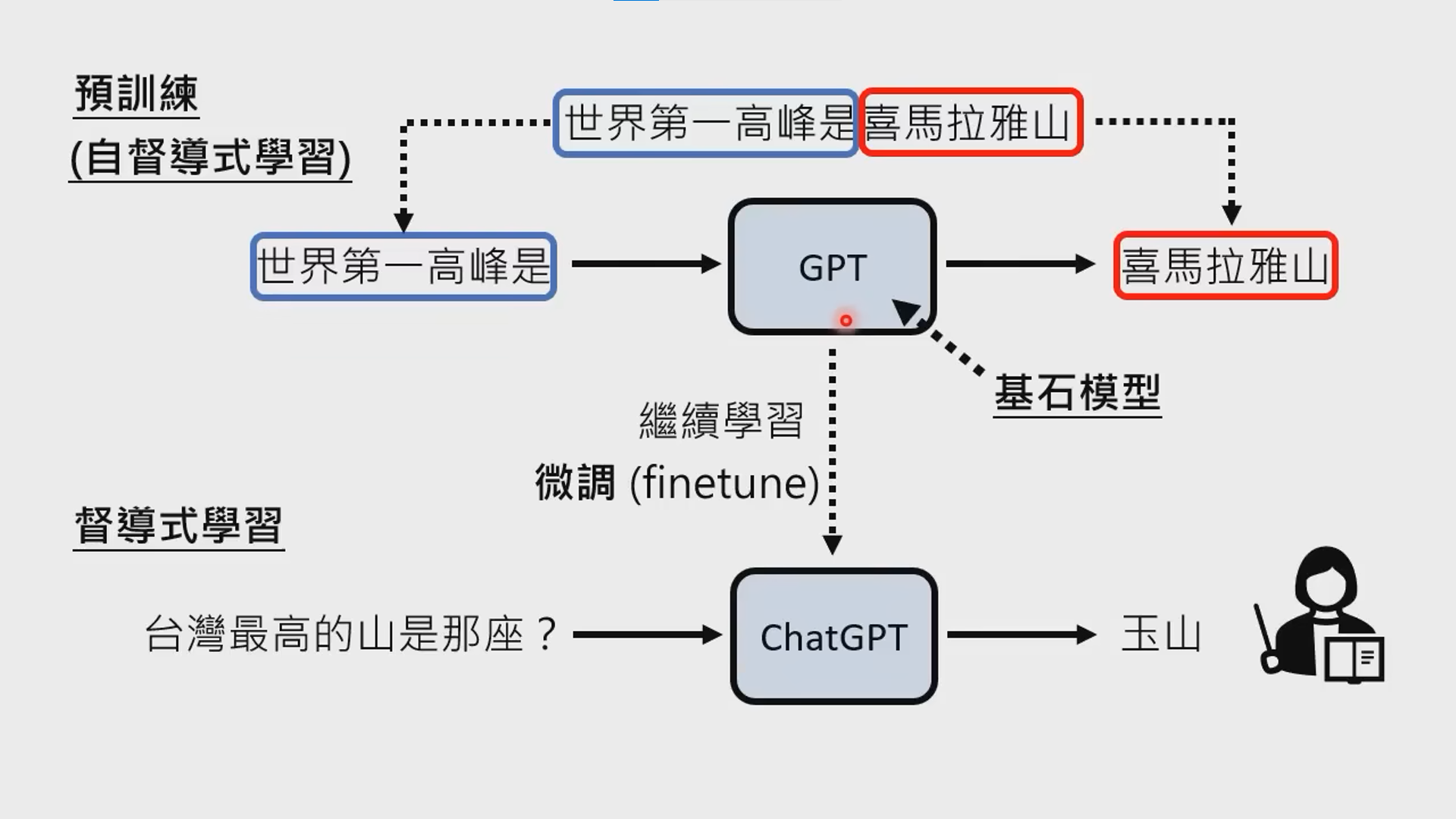
先解释 one-shot。公司门禁用了人脸识别,你只提供一张照片,门禁就能认识各个角度的你,这就是 one-shot。可以把 one-shot 理解为用 1 条数据 finetune 模型。在人脸识别场景里,one-shot 很常见。
zero-shot 与 few-shot,回到 NLP 场景。用 wikipedia、新闻等,训练一个 GPT 模型,直接拿来做对话任务,这个就是 zero-shot。然后,发现胡说八道有点多,找了一些人标注了少量优质数据喂进去,这就是 few-shot。
chatGPT 的发展史,就是从 zero-shot 到 few-shot。
- 背景。GPT-3 之前,跟 Bert 是两条路线的竞争关系。
- GPT-2 是 zero-shot。效果没有超过 bert,又想发 paper,就把自己的卖点定义为 zero-shot(方法创新),即完全的无监督学习,论文的题目:Language Models are Unsupervised Multitask Learners。
- GPT-3 是 few-shot。效果比 bert 好,不用找学术方法的卖点了,而且,zero-shot 做产品的性价比确实不高,换成了 few-shot,也就是找了一些人做标注。论文的题目:Language Models are Few-Shot Learners。
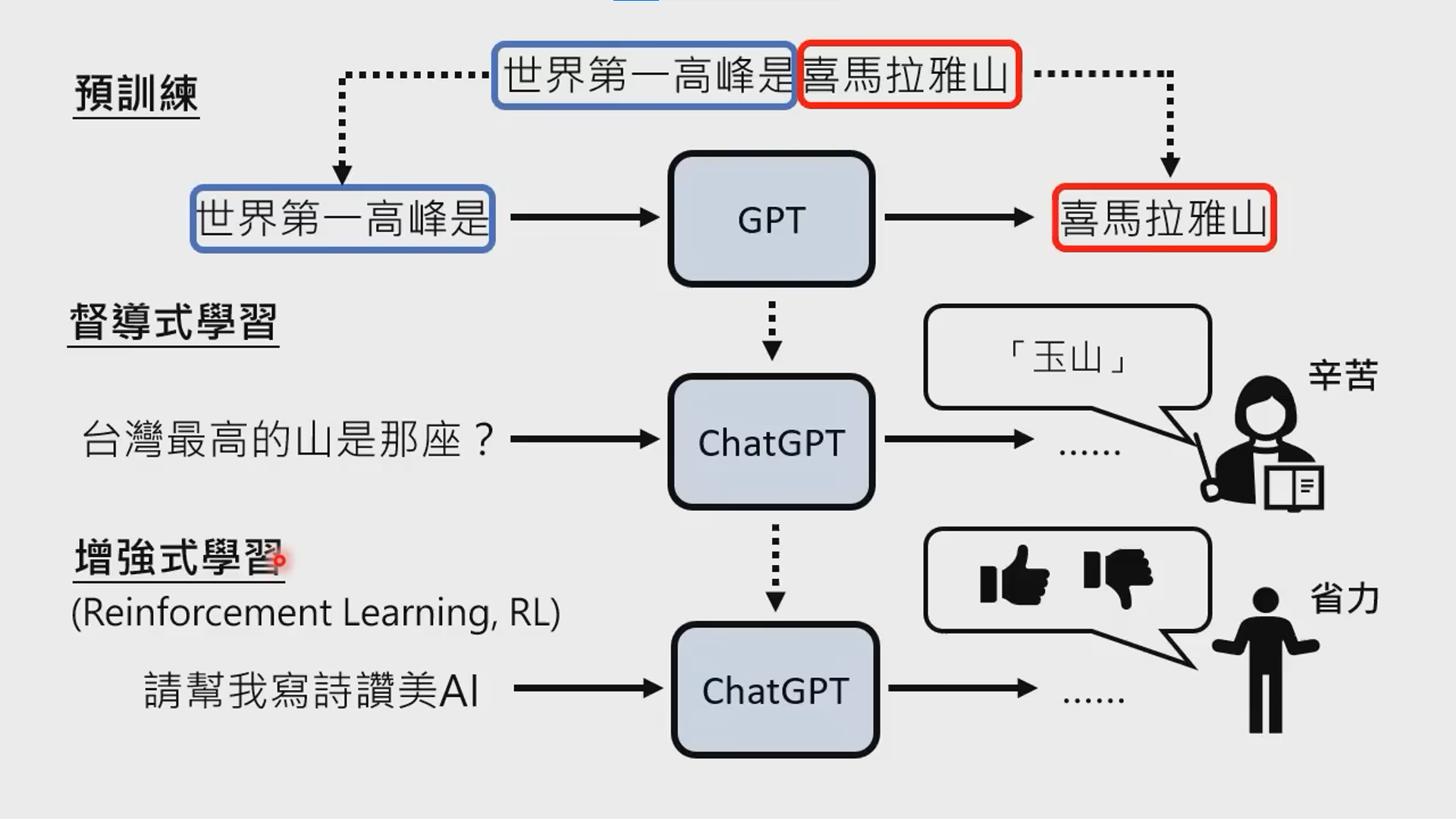
- chatGPT 是 HFRL。GPT-3 之后的问题是:few-shot 时到底 shot 啥(标注哪些数据)?他们跟强化学习结合起来,也就是 human feedback reenforcement learning,俗称 HFRL。也就是 chatGPT 的核心技术。HRFL 这套方法,本质目的是:如何把机器的知识与人的知识对齐。然后开创了一个新的方向,叫 alignment。
AR模型,代表作GPT,从左往右学习的模型。AR模型从一系列time steps中学习,并将上一步的结果作为回归模型的输入,以预测下一个time step的值。AR模型通常用于生成式任务,在长文本的生成能力很强,比如自然语言生成(NLG)领域的任务:摘要、翻译或抽象问答。
刚刚提到,AR模型会观察之前time steps的内在联系,用以预测下一个time step的值。如果两个变量朝着同一方向变化,比如同时增加或减少,则是正相关的;若变量朝着相反的方向变化,比如一个增加另一个减少,则是负相关的。无论是什么样的变化方式,我们都可以量化输出与之前变量的关系。这种相关性(正相关 or 负相关)越高,过去预测未来的可能性就越大;在深度学习训练过程中,对应的模型权重也就越高。由于这种相关性是在过去time steps中,变量与其自身之间的相关性,因此也称为自相关性(autocorrelation)。此外,如果每个变量与输出变量几乎没有相关性,则可能无法预测。
AR模型利用上/下文词,通过估计文本语料库的概率分布,预测下一个词。
给定一个文本序列, \(x=\left(x_1, \ldots x_T\right)\) 。AR模型可以将似然因式分解为
前向连乘: \(p(x)=\prod_{t=1}^T p\left(x_t \mid x_{<t}\right)\)
或者后向连乘: \(p(x)=\prod_{t=T}^1 p\left(x_t \mid x_{>t}\right)\)
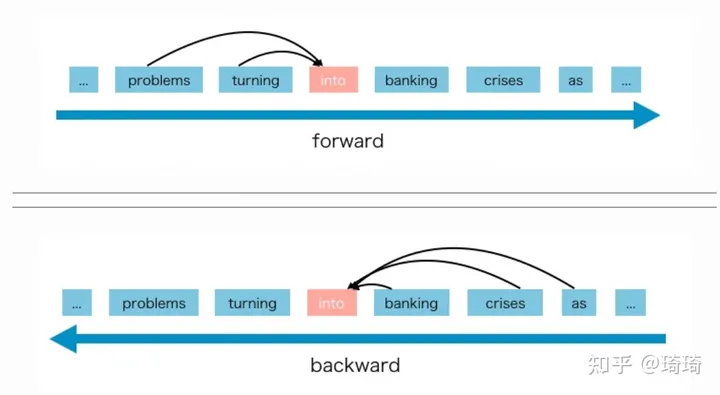
我们知道,训练参数模型 (比如神经网络) ,是用来拟合条件概率分布的。AR语言模型仅仅是单向编码的 (前向或后向),因此它在建模双向上下文时,效果不佳。下图清晰解释了AR模型的前向/后向性。
问:GPT3像one shot和few short zero shot这些训练方式还是不太明白,不太明白为什么可以在不更新权重的情况下进行学习?
答:few shot是在输入里增加了更多和目标输出相关的文本,这些文本会作为模型decoder的输入去产生输出,decoder的输入部分增加了有用的东西自然就更容易产生有用的输出。
References
Concept:
[1] 万字长文——这次彻底了解LLM大语言模型-腾讯云开发者社区-腾讯云 (tencent.com)
[2] LLM面面观之Prefix LM vs Causal LM - 知乎 (zhihu.com)
Note:
[3] 白话机器学习-Attention - 知乎 (zhihu.com)
[4] 白话机器学习-Self Attention - 知乎 (zhihu.com)
[5] 白话机器学习-Encoder-Decoder框架 - 知乎 (zhihu.com)
[6] 从RNN、LSTM到Encoder-Decoder框架、注意力机制、Transformer - 知乎 (zhihu.com)